A beginner-friendly introduction to compilers: follow along as we build a compiler from scratch, or fork the code on GitHub and add your own optimizations too! In this episode: eliminating no-op instructions.
What part of computer science feels most like arcane magic? I'd say compilers. "The magical incantation gcc -O3 file.c makes my program run 10x faster in ways I don't understand" sure sounds like arcane magic. Modern compilers are the product of engineer-centuries of work, so it's unsurprising they feel intimidating.
 View of the Victoria Falls of the Zambezi River, the largest sheet of falling water in the world. A scene of immense arcane power, perhaps similar to the arcane power of compilers.
Source:
Diego Delso, delso.photo, CC BY-SA
View of the Victoria Falls of the Zambezi River, the largest sheet of falling water in the world. A scene of immense arcane power, perhaps similar to the arcane power of compilers.
Source:
Diego Delso, delso.photo, CC BY-SA
{kind=link}
But there's no law of the universe that says compilers have to be complex and difficult to understand. [Sidenote: In fact, simple compilers are everywhere. We just don't tend to notice that many tools fit the description of a compiler: a tool that takes input, analyzes it and performs some transformations on it, and produces output.] In this blog post series, we'll build a compiler from scratch, one straightforward step at a time. Each blog post will tackle a facet of the compiler, and over time, our optimizations will add up to create arcane magic of our own.
Our compiler will optimize the simple MONAD programming language from Advent of Code 2021 day 24. However, this is not a guide to solving Advent of Code 2021 day 24, even though there will definitely be spoilers. Instead, our goal is to learn about compilers and have fun doing it. We’ll prioritize simple code and clear explanations of compiler ideas over everything else.
Even so, the techniques we cover here can generate some pretty impressive numbers! The Advent of Code challenge has 22 trillion possible answers, and Matt Keeter's blog says that without optimizations, checking all of them would take more than 3.5 years. The compiler techniques from this series can find the answer in 0.16 seconds, more than 700 million times faster. Not bad at all, right?
Getting started
We’ll write our compiler in Rust because of its excellent ergonomics, but knowing Rust isn’t a requirement for enjoying this series. Our compiler will be built from the most common data structures: tuples, maps (dictionaries), vectors (lists), etc. For example, Python's Tuple[int, int] and List[str] type hints become (i64, i64) and Vec<String> in Rust, respectively. Another Rust type to know is usize: that's Rust's preferred unsigned integer type for counting and indexing operations.
When reading the code, feel free to mentally replace usize with int if coming from another programming language, like Python. [Sidenote: If you aren't familiar with Rust but are interested in learning it, the Rust Book is an excellent free online resource (also available in print), and Rust in Action is an excellent book on learning Rust with an emphasis on systems programming in particular.]
All the code in this series is available on GitHub — feel free to fork the repo to follow along and make your own changes and optimizations as well! Each episode's start and finish points will have an associated git branch. This episode starts on branch part1.
Representing a MONAD program
Here is a quick intro to the MONAD programming language from Advent of Code 2021 day 24. MONAD supports only four variables w, x, y, z (called "registers" in compiler terminology), and has six instructions that operate on them:
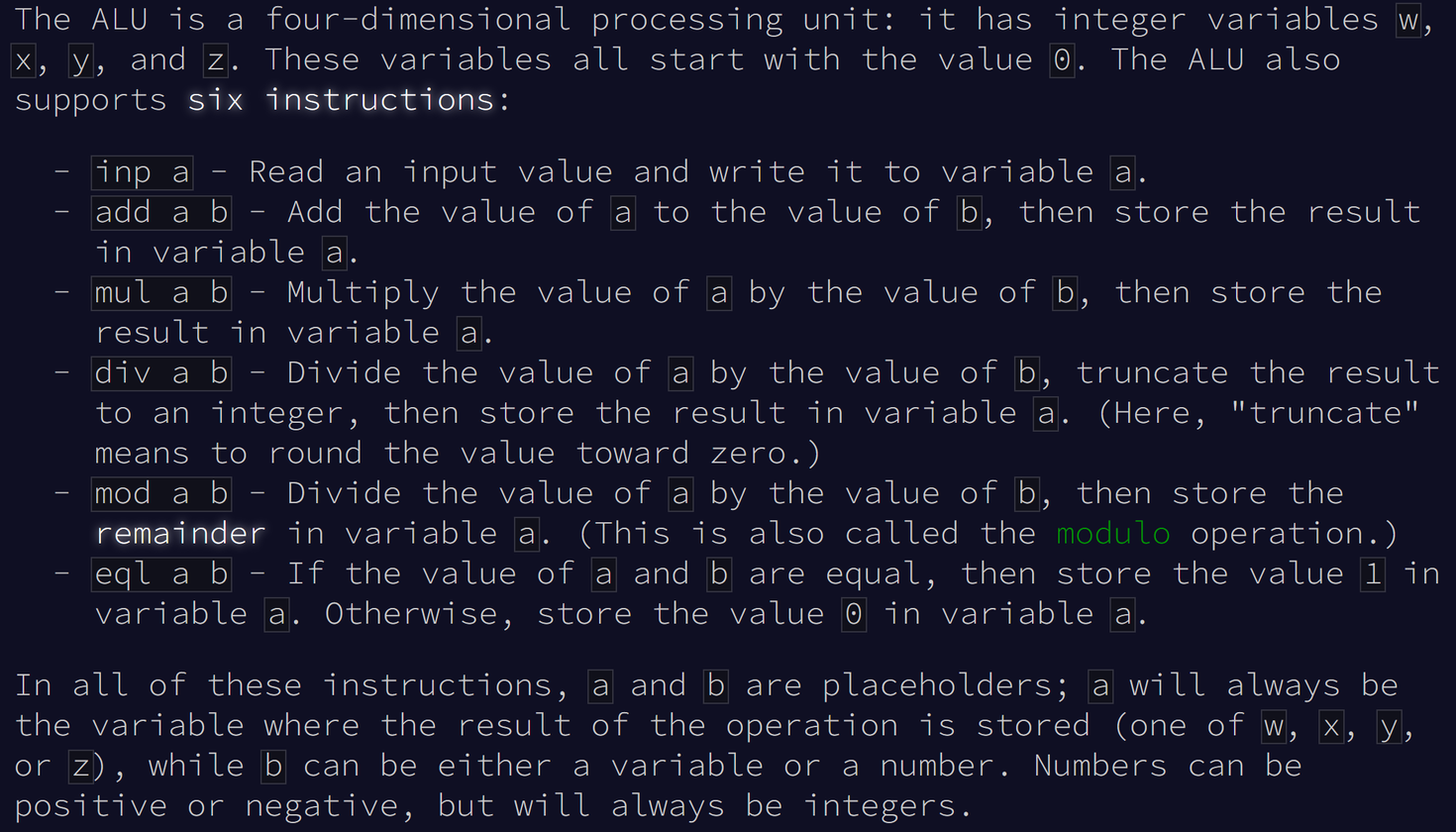 The six instructions available in the MONAD programming language. Screenshot from Advent of Code 2021 day 24.
The six instructions available in the MONAD programming language. Screenshot from Advent of Code 2021 day 24.
We'll represent w, x, y, z as Register(0) through Register(3), which all have starting values of 0 at the beginning of a MONAD program. The six instructions can use any register, and sometimes take a second parameter which may be either a literal number or a register.
program.rs. See this code in context in the GitHub repo.
Based on this structure, MONAD instructions like mul w 2 — "multiply w by 2 and store the result in w" — would become Instruction::Mul(Register(0), Operand::Literal(2)).
If the instruction specifies register x instead of the number 2, the operand value would instead be Operand::Register(Register(1)): the Operand::Register enum variant with the struct Register(1) inside. [Sidenote: The repetition of Register is a bit unfortunate. It is, however, idiomatic Rust to put structs inside enum variants of the same name. In principle, we could replace Register with usize everywhere, but then instructions would become a bit harder to read: mul w 2 would become Instruction::Mul(0, Operand::Literal(2)), which reads dangerously close to 0 * 2 instead of w * 2.]
For this blog post, let's assume we already have a way to parse a MONAD program into a list (Vec) of Instruction elements. This is a series on compilers, not parsers! But if you're curious how the parser works, here is a link to the function that will do our parsing.
Our first optimization
The key to developing optimizations is looking at a program and thinking about how it might be improved without changing its meaning. Here are the first 5 instructions in the input program from Advent of Code:
inp w
mul x 0
add x z
mod x 26
div z 1In our Rust representation, the parsed program would look like:
Take a look at that last instruction: div z 1. We are dividing a number by ... one. That doesn't seem like it does much, does it? We don't know the value of z, but that doesn't matter: the value of z remains unchanged regardless of what it was.
Optimizing a program means finding more efficient ways to execute parts of the program without the rest of the program noticing. For example, imagine we are executing this program, and when div z 1 is the next instruction to execute, we simply skip it instead of executing it. Will anything in the program behave differently as a result? Definitely not — all the w, x, y, z registers will still have correct values — so we can optimize the program by removing that instruction.
Let's formalize our idea: we plan on looking through our list of instructions, and every time we see an instruction that says "divide by the value 1", we simply discard it:
optimization.rs. See this code in context in the GitHub repo.
Congratulations, we just created our first optimization pass: [Sidenote: A quick note for experienced Rustaceans: I know this code isn't idiomatic Rust. I'm intentionally structuring the code to make it easier to understand for people of any background. Using .into_iter().filter(...).collect() would take the focus away from the compiler and move it onto Rust language features.]
a flavor of redundant code elimination, called that because it eliminates code that has no influence over the rest of the program. This kind of "do-nothing" instruction is usually called a "no-op". Let's run the optimization on our Advent of Code input program and measure how well we did:
$ cargo run analyze sample_programs/aoc_challenge.txt
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `.../monad_compiler analyze sample_programs/aoc_challenge.txt`
Original vs optimized length: 252 vs 245 (-7)
Optimized is more efficient by: 2.86%With this simple 16-line optimization, we've already eliminated 7 no-op instructions and optimized the program by about 3% — and we're just getting started!
The bigger picture
Right now, one might think: “What a silly little optimization, surely we didn’t need a compiler for this?” In a narrow sense, that's correct: we could have found and removed all the “divide by 1” instructions by hand (or used a regex like div [wxyz] 1 to remove them) and gotten the same 3% improvement.
However, even the most sophisticated compilers are just a collection of individually-simple rules like the one we just implemented. While each rule by itself may feel too trivial to be valuable, the combination of all the rules working together is the source of all compilers’ power. Running one optimization can unlock opportunities to perform other optimizations as well, and thus the whole becomes greater than the sum of its parts!
Most programs contain little if any obviously-redundant code like division by one. Our Advent of Code input program is no exception. But it's good to get the easier wins first, especially when that makes our future work easier. Many of our future optimizations will be much simpler to implement knowing that any such redundant code they discover or create is not something they'll have to worry about.
This optimization currently has only a 3% impact. But the next Compiler Adventure episode will already rely on redundant code elimination as a component of a more sophisticated optimization pass, making the overall effect much higher.
Wrap up & challenge question
The completed code at the end of this post is on branch part1_finished in the GitHub repo. The next Compiler Adventure will pick up here and introduce another optimization.
Here's a little challenge in the meantime: there are two other instructions that have a no-op case like div z 1, where the instruction is a no-op regardless of the register's value. Can you figure out what they are? We'll solve this and more next time — see you in the next Compiler Adventure!
If you liked this post, please share it with friends — compilers are for everyone! Reach out to me on Twitter or join the discussion on HackerNews.
Thanks to Hillel Wayne, Russell Cohen, Jonathan Paulson, Jimmy Koppel, Aaron Brooks, Vincent Tjeng, James Logan, and Akshat Bubna for their feedback on drafts of this post. Any mistakes are mine alone.