Last month, I gave a talk titled "SemVer in Rust: Breakage, Tooling, and Edge Cases" at the FOSDEM 2024 conference.
The talk is a practical look at what semantic versioning (SemVer) buys us, why SemVer goes wrong in practice, and how the cargo-semver-checks linter can help prevent the damage caused by SemVer breakage.
TL;DR: SemVer is impossibly hard for humans, but automated tools can cover our greatest weaknesses. [Sidenote: This is common theme in Rust, isn't it? At scale, lots of problems are too hard for humans. Memory safety is too hard, so Rust has the borrow checker. Parallelism is too hard, so we have the compiler help us. And so on...]
Full talk abstract (click to expand)
In theory, semantic versioning (SemVer) is simple: breaking changes require major versions. SemVer rules do not change over time. Crates always adhere to SemVer. Careful coding is enough to avoid accidental breaking changes.
None of those statements are true!
In practice, SemVer is complex and accidental breakage is common: 1 in 6 of the top 1000 Rust crates has violated semantic versioning at least once, frustrating both users and maintainers alike.
If you write Rust but don't have the time for a PhD in SemVer, this talk is for you. We'll take a practical look at SemVer in Rust: what it buys us, how Rust's features lead to strange SemVer edge cases, and how we can prevent accidental breakage using a SemVer linter called cargo-semver-checks.
You can watch my talk on YouTube, or embedded below. [Sidenote: An A/V equipment failure during my talk caused 10min of my talk to be missing from the official FOSDEM recording. I re-recorded the missing portion, and edited it into a complete video of the talk — that's the version I'm including here.] Read on for an annotated version of the talk, [Sidenote: I believe Simon Willison coined the term "annotated talk", and described it on his blog. I like this idea, and I'm broadly aiming to follow the same approach.] covering the same ideas in written form and including some additional content that did not make it into the talk due to time constraints.
The talk video and outline are below, so you can jump ahead or switch between the written and video formats as you like.
Outline
- What semantic versioning (SemVer) buys us
- SemVer is hard — we keep breaking it by accident
- Everyone loses when accidental SemVer breakage happens
- Why "just be more careful" won't fix it
- SemVer's rules are much more complex than they seem
- How cargo-semver-checks fits into the picture
- cargo-semver-checks lints are database queries in disguise
- A peek at Trustfall, an engine for querying everything
- Conclusion: Solving maintainability led to a tool that users love
What semantic versioning (SemVer) buys us
Jump to this chapter in the video.
SemVer is about communication.
It's a way for library maintainers to communicate with users, and with the tooling those users use. It sets expectations on the amount and nature of work required to adopt a new version of a library.
If the changes are substantial and may require action from the user of the library, we say that's a major change. The maintainer would bump the major version number, and users will know that this version upgrade might require a bit of work to adopt. Automated tooling will usually avoid making this kind of upgrade on its own. [Sidenote: Some ecosystems and companies have created "codemod" systems, which can automatically refactor downstream code to make it comply with breaking API changes. This makes it possible to apply major changes automatically, but it requires a substantial amount of extra work on top of a large amount of pre-existing infrastructure.]
Otherwise, if the library remains compatible with the previous version, users expect their automated tooling to take care of upgrading them. This is great! They benefit from performance upgrades, security patches, and new functionality — and (in the ideal case) no human time was spent to get those benefits.
Here's a concrete example.
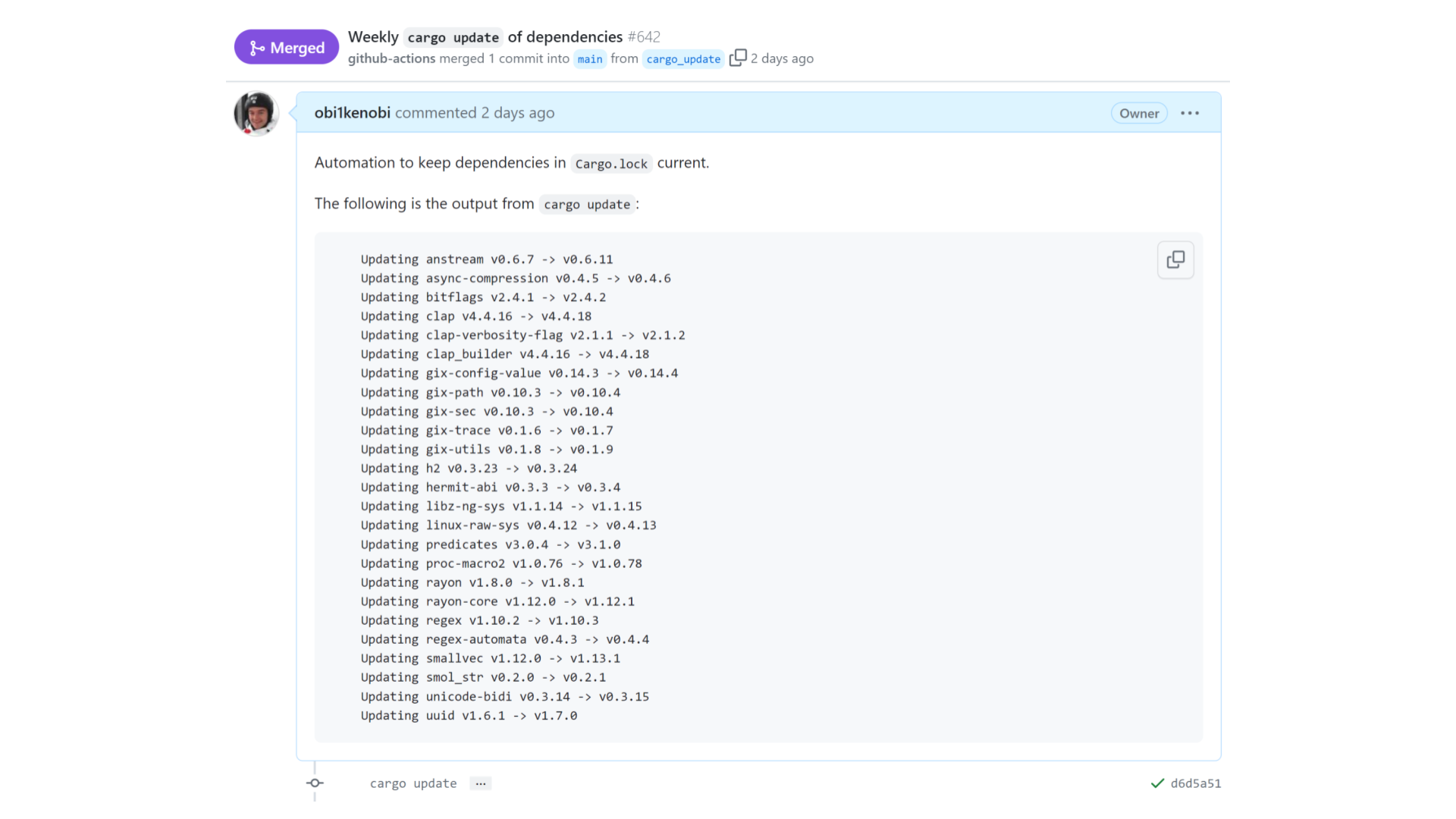
Many of my projects have a job that runs cargo update once a week, commits the results, opens a pull request, and merges it automatically if CI passes.
In this example, we just got 25 libraries' worth of improvements — without requiring any time investment from this project's maintainers. Excellent! This frees up maintainers to invest their limited time elsewhere, starting a virtuous cycle that leaves the entire community better off. [Sidenote: To see why this is such a big deal, imagine manually bumping versions in a project with a dependency tree as big as this one — yikes! 😱]
But this only works as long as none of these dependencies have accidentally violated SemVer. [Sidenote: And so long as they use SemVer in the first place. SemVer is not the only versioning scheme, but it's overwhelmingly common in Rust since cargo update by default assumes all crates adhere to SemVer. In other language ecosystems, this kind of automation might not work as well as it does in Rust.]
If a breaking change has accidentally slipped into one of these versions, then our CI run fails, the pull request doesn't get merged, and a maintainer has to intervene to fix the problem manually. Our automation didn't work, so we're back to square one.
Overview: SemVer is hard, but automation can help
Jump to this chapter in the video.
I'm going to convince you of two major things.

First, that semantic versioning in practice is so hard that no mere mortals can uphold it. None of us are good enough to do it on a consistent basis.
I'll show you that the rules of semantic versioning are much more complex than they seem.
I'll show you that even the rules that seem simple have a ton of non-obvious edge cases.
And I'll show you empirical evidence based on real world data that this is not a skill issue. It's not something that can be solved with more experience, or with harder work, or just by caring more about your projects and your users.

Then I'll show you that computers are really good at semantic versioning.
We can use linters like cargo-semver-checks to address almost all of the problems we're going to run into as part of this talk.
And I'll even show you how cargo-semver-checks works under the hood, so you can trust its results and so you can contribute to it for the benefit of all of us in the Rust community.
SemVer is hard — we keep breaking it by accident
Jump to this chapter in the video.
Throughout this talk, we'll go through a series of falsehoods about SemVer in Rust. Each of those statements will sounds plausible and reasonable, but is actually false. This is how we'll get a sense of how hard SemVer really is.
Our first falsehood: Rust crates always adhere to SemVer.

If you've been part of the Rust ecosystem for long enough, you know this to be false.
Issues reporting breaking changes get opened everywhere all the time.
This last one perfectly sums up the issue: the breakage wasn't intended, it was accidental.
No maintainer wakes up in the morning and says: "I'm going to break the entire ecosystem today."
Everyone loses when accidental SemVer breakage happens
Jump to this chapter in the video.
SemVer breakage is a lose-lose all around.
Everyone is worse off: maintainers, downstream users, and the community as a whole.
From a maintainer's perspective, nobody likes to see an issue like this get reported.
None of us like realizing that we accidentally broke the entire ecosystem.
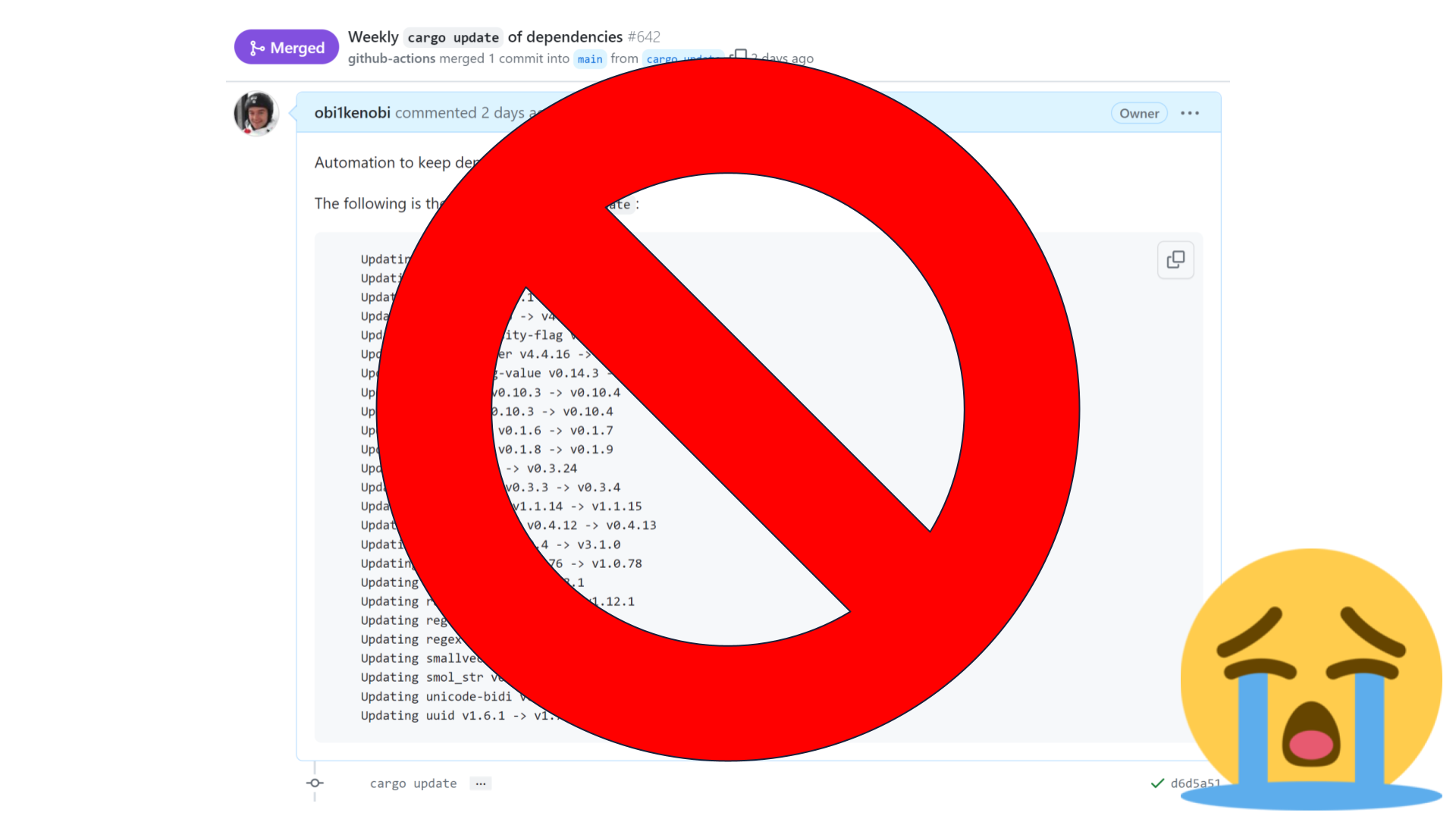
As a user, we lose because our automation doesn't work and our project's build might be broken.
We no longer get improvements "for free." Instead, we have to update our dependencies manually.
In a large project with many dependencies, this could be a huge amount of work.
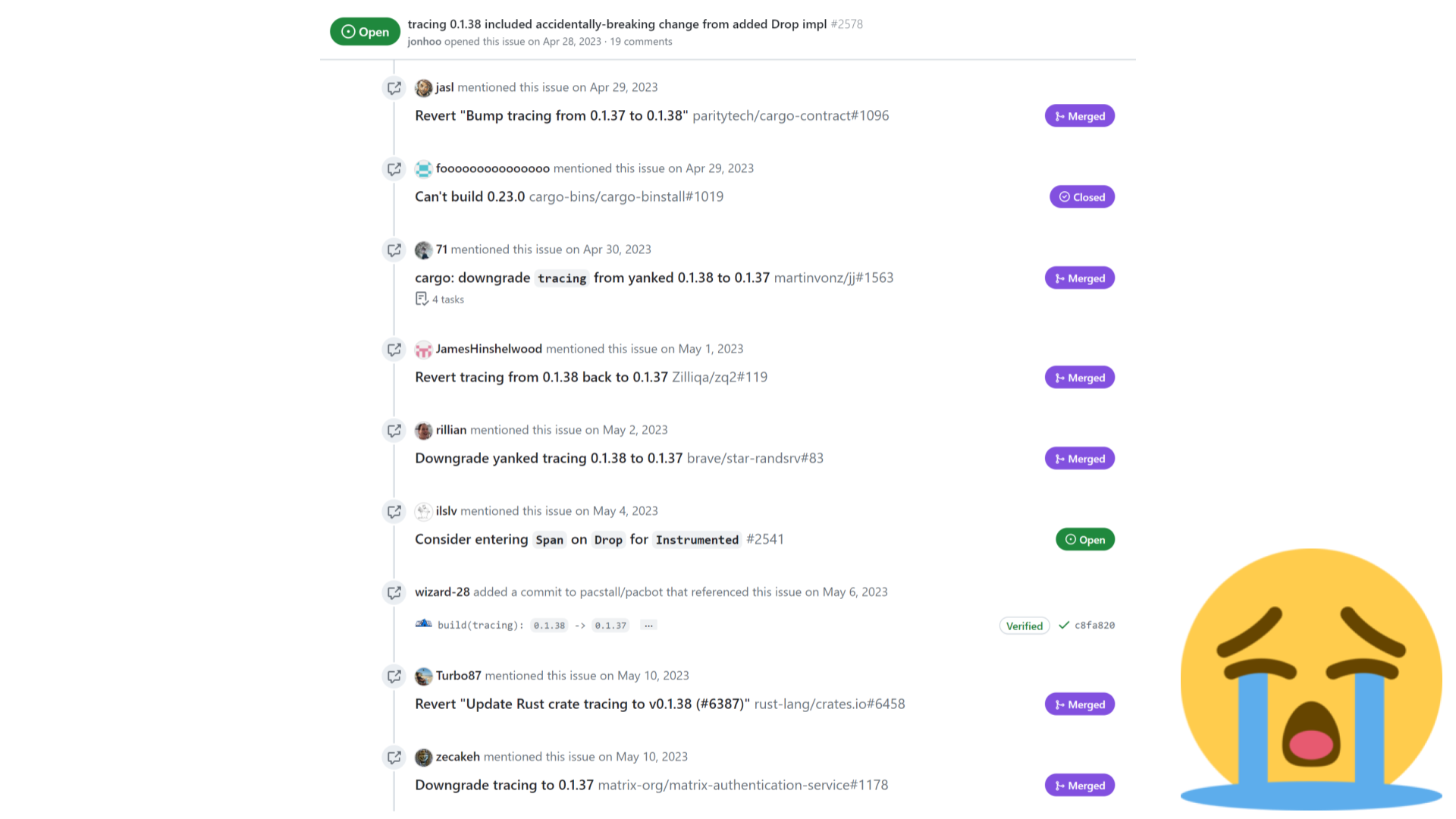
From an ecosystem perspective, the breakage means a lot of work across many projects needs to happen just to make everyone's build start passing again.
The screenshot above is just a fraction of all the issues and commits referencing that particular accidental breakage.
This work is stressful, disruptive, and ultimately unproductive. Maintainers have to drop what they were doing, and instead do work that doesn't lead to any new features nor performance improvements.
It's pure wasted effort, community-wide.

SemVer is about communication, so SemVer violations are miscommunication.
When a release goes out with the wrong version number, it sets incorrect expectations with users and their tooling. Then the tooling fails and we all end up frustrated.
This is expensive miscommunication! All of us would be much better off if it didn't happen. Even if our own projects aren't directly affected by a given breakage incident, we'd all prefer if the maintainers of our tools and dependencies could invest their limited time toward more productive endeavors.
So why does breakage keep happening?
Why "just be more careful" won't fix it
Jump to this chapter in the video.
At this point, one might think that maybe we should "just" be more careful. Maybe this is a skill issue! Maybe the answer is to "just get good." [Sidenote: For any readers unfamiliar with the phrase, this is a reference to "git gud", a phrase coined in gaming culture. It's used as an unconstructive response, implying that "real" gamers (in our case, serious maintainers) don't have the indicated problem — they learn to overcome it through hard work and skill. In SemVer's case, that won't work — "would that it were so simple!"]

This is another falsehood.
Careful coding is not enough to avoid SemVer violations.

That's right. More than 1 in 6 of our most popular crates have shipped a SemVer violation at least once.
These are the crates that are maintained by the most experienced, most careful maintainers in our entire community. Without a doubt, they've personally experienced the pain of accidental SemVer breakage. If they can't get semantic versioning right day in and day out, what hope is there for the rest of us?!
This is data that we gathered by running cargo-semver-checks. We worked hard to ensure our results are faithful and not just the result of false-positives. [Sidenote: Regular readers may remember reading about our process on this blog, or seeing the discussion about our results on r/rust. For example, the maintainer of the time crate requested to see our findings for their crate, and we discussed them here.]

As part of the study, we scanned more than 14000 releases.
More than 3% of them had at least one semantic versioning violation that cargo-semver-checks discovered and would have prevented.
To put this 3% number in context:
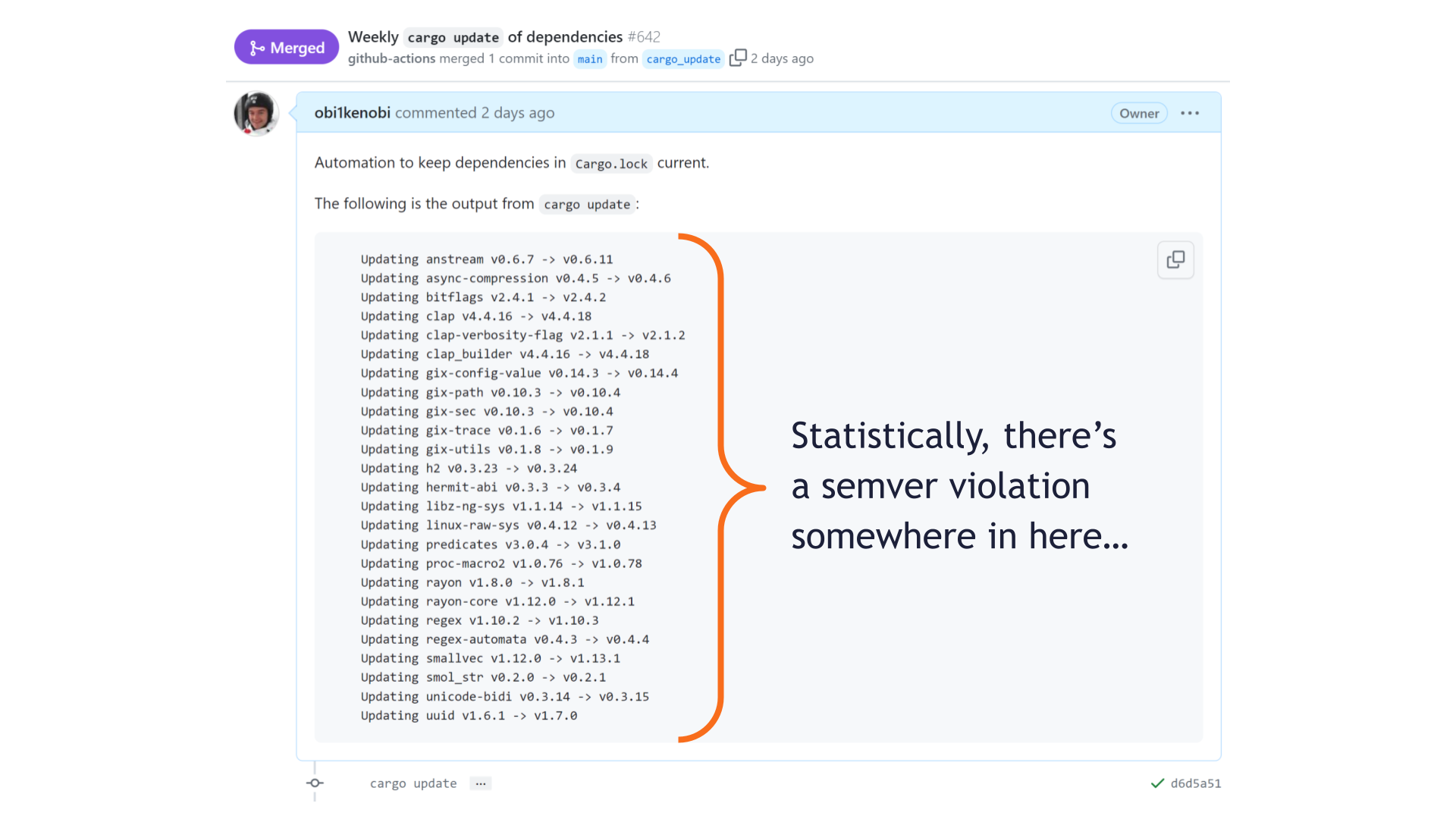
Statistically, we shouldn't be surprised if a SemVer violation is lurking somewhere in these updated crates.
Now, this pull request happened to pass our tests just fine. Maybe we got lucky, and there is no SemVer violation. Maybe we just weren't affected by it this time.
But luck is not a strategy. With a breakage rate that high, many pull requests like this one will fail due to accidental breakage. That's just the cost for one project — multiply it out across the entire community and the cost quickly gets out of hand.
SemVer's rules are much more complex than they seem
Jump to this chapter in the video.

Another surprising falsehood is that not all breaking changes require major versions in Rust.
For this, we need to consult Rust's API evolution RFC 1105.
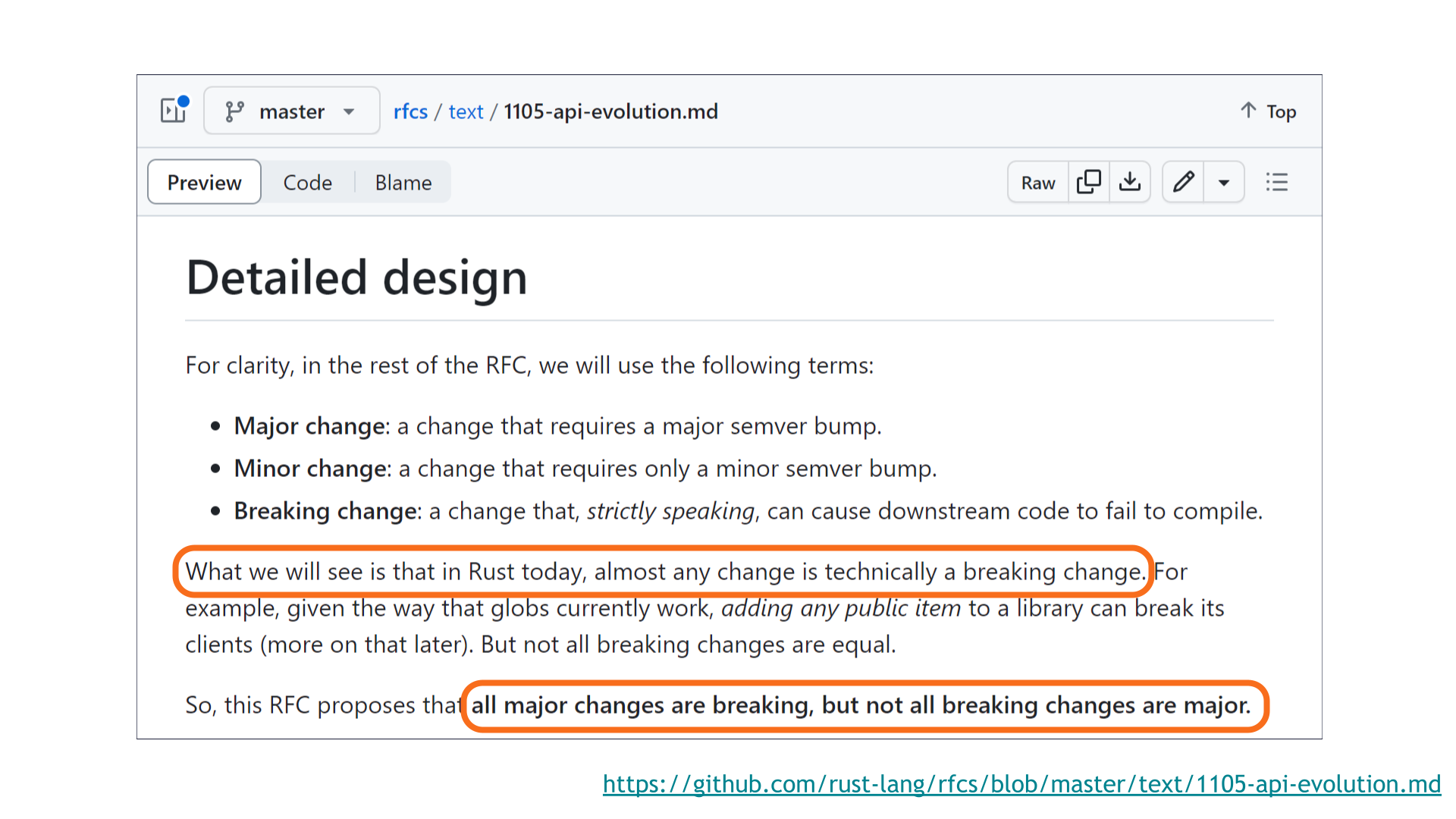
In Rust today, almost any change is technically a breaking change! [Sidenote: Regular readers may recall my blog post on this exact topic.]
A rules-first approach would require almost every new release of a Rust crate to come with a major version bump. This isn't helpful! This is why SemVer isn't about the rules — it's about communication.
For example, if almost every release is a major bump, then our dependency-updating automation still wouldn't work. And all this because of some changes that are technically breaking — but where that breakage in practice is avoidable, is extremely rare, or is only triggered by particularly convoluted code that is inadvisable to write in the first place.
This is why not all breaking changes are major. [Sidenote: Surprisingly, this isn't unique to Rust! What's unique to Rust is that this rule is explicitly written down in an easy-to-cite place. You'll see shortly that many of the "breaking but not major" cases clearly apply to other programming languages too.]
The rules of SemVer are meant to serve users, not vice versa. This is the choice that best serves users.
Here are some of the breaking changes that are not major. These are merely the most common edge cases — there are more!
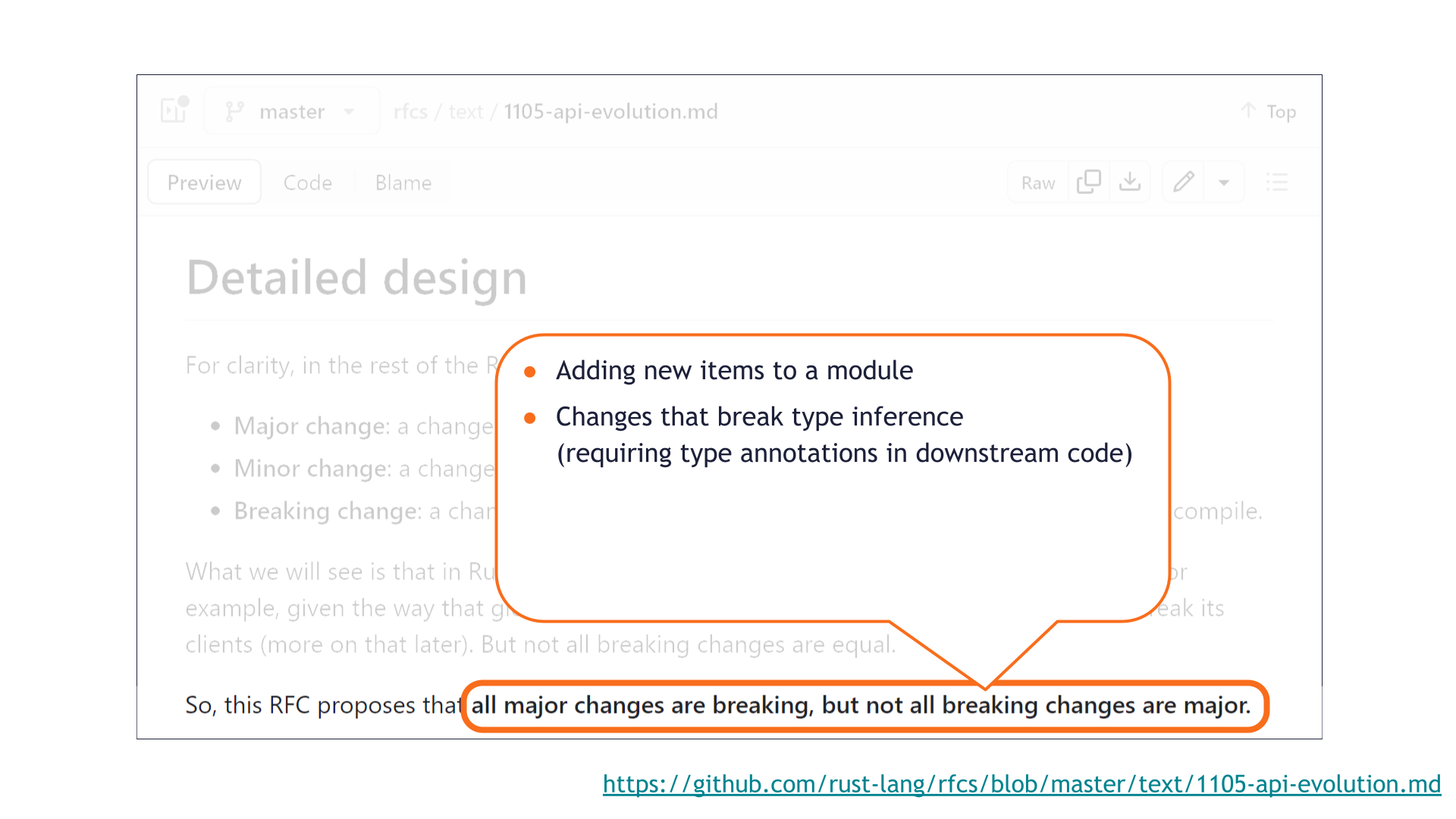
The first one is that adding new items to a module is technically a breaking change.
This is because of some quirks related to glob imports.
I think we'd all agree that adding new functionality to a library should not in general be a major change, so it makes sense that this is considered minor even though it's breaking. [Sidenote: Nearly all languages that support glob imports have the same breakage case! For example, exposing a new non-underscored function in Python is also a breaking change — a one-to-one Python translation of the Rust code here will demonstrate it. Most languages implicitly agree that this type of breakage "doesn't count" for SemVer purposes; Rust merely made that rule explicit by writing it down.]
Another example is that breaking type inference is not considered major.
This is because it's possible to avoid being broken by such a change by adding explicit type annotations in downstream code. In principle, better tooling should be able to add these kinds of type annotations when they become necessary. In the future, this change might no longer be breaking — so it's a reasonable choice to make it non-major today.
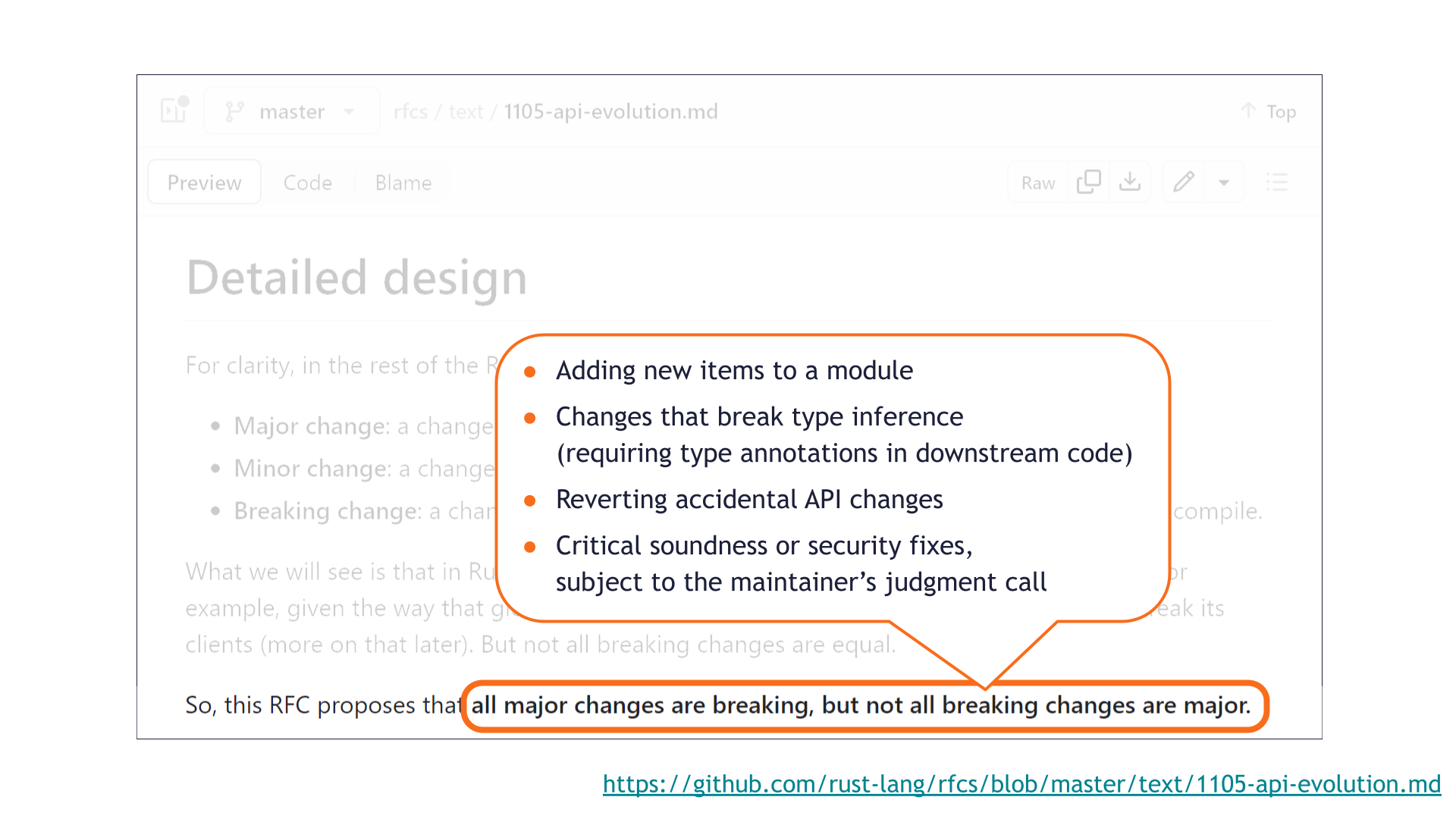
A third example is reverting accidental API changes. [Sidenote: Again, not unique to Rust! Rust just wrote it down explicitly.]
This is something we ran into as part of our SemVer study. A few times, a maintainer had accidentally caused a private portion of their library to become public API. It would be extremely unfortunate if undoing that accident required a major bump, even if it was caused and corrected mere minutes apart.
The last example is that critical soundness or security fixes can be published in minor changes even if they are breaking. [Sidenote: Not unique to Rust either!]
This again comes back to "SemVer is about communication."
Semantic versioning allows the maintainer to make a judgment call about what is the lesser evil: whether it's more dangerous to risk letting the soundness or security vulnerability persist, or to break everyone's build.
If the vulnerability is bad enough, forcing faster adoption by breaking everyone's build might be the better outcome overall.
This is not a complete list of all the edge cases! For more details, including a code example of how adding a new public item is a breaking change, check out this post.

Zooming out — we've already seen three reasonable-looking statements that turned out to be false. We're just getting started!
The takeaway so far is that SemVer is hard.
There are many rules with many edge cases. Learning all the rules means earning a PhD in SemVer. Following all the rules requires superhuman attention to detail. The odds are stacked against us!
Say we cared about SemVer so much that we forced all maintainers to learn all the rules, then demanded perfect SemVer adherence at all costs. We'd have SemVer, but at what cost? Progress would grind to a halt!
Instead we'd like to accelerate the pace of development. We can only do that by drastically lowering the cost of SemVer adherence.
Automation like cargo-semver-checks is how we do that. This is the way!
How cargo-semver-checks fits into the picture
Jump to this chapter in the video.
Computers are really good at SemVer.
They can't do everything — the Halting Problem gets in the way as usual. But our abilities are complementary: computers are the best where we do poorly, and vice versa.
cargo-semver-checks is a SemVer linter that is broadly adopted across the Rust ecosystem.
It's used by fundamental Rust crates like tokio and PyO3.
Cargo itself uses cargo-semver-checks to check its own library components.
Companies like Amazon and Google use it to prevent breaking changes in the crates they publish.

cargo-semver-checks is designed to be used as: cargo semver-checks && cargo publish.
It detects the kind of version bump that you're making (major, minor, or patch), then scans for API changes that might be inappropriate for that bump.
You can get cargo-semver-checks through cargo install, or by downloading a pre-built binary.
Release managers like release-plz can automatically run cargo-semver-checks as part of publishing your crate, and we have a GitHub Action designed to be used in CI, [Sidenote: Today, that GitHub Action is most suitable for use as part of a CI publishing pipeline, and is not a great fit for running on individual pull requests. This is something we plan to fix! The limiting factor is finding a sustainable source of funding for the project. We'd love your help!]
Example: Can deleting a pub fn not be a breaking change?
Jump to this chapter in the video.
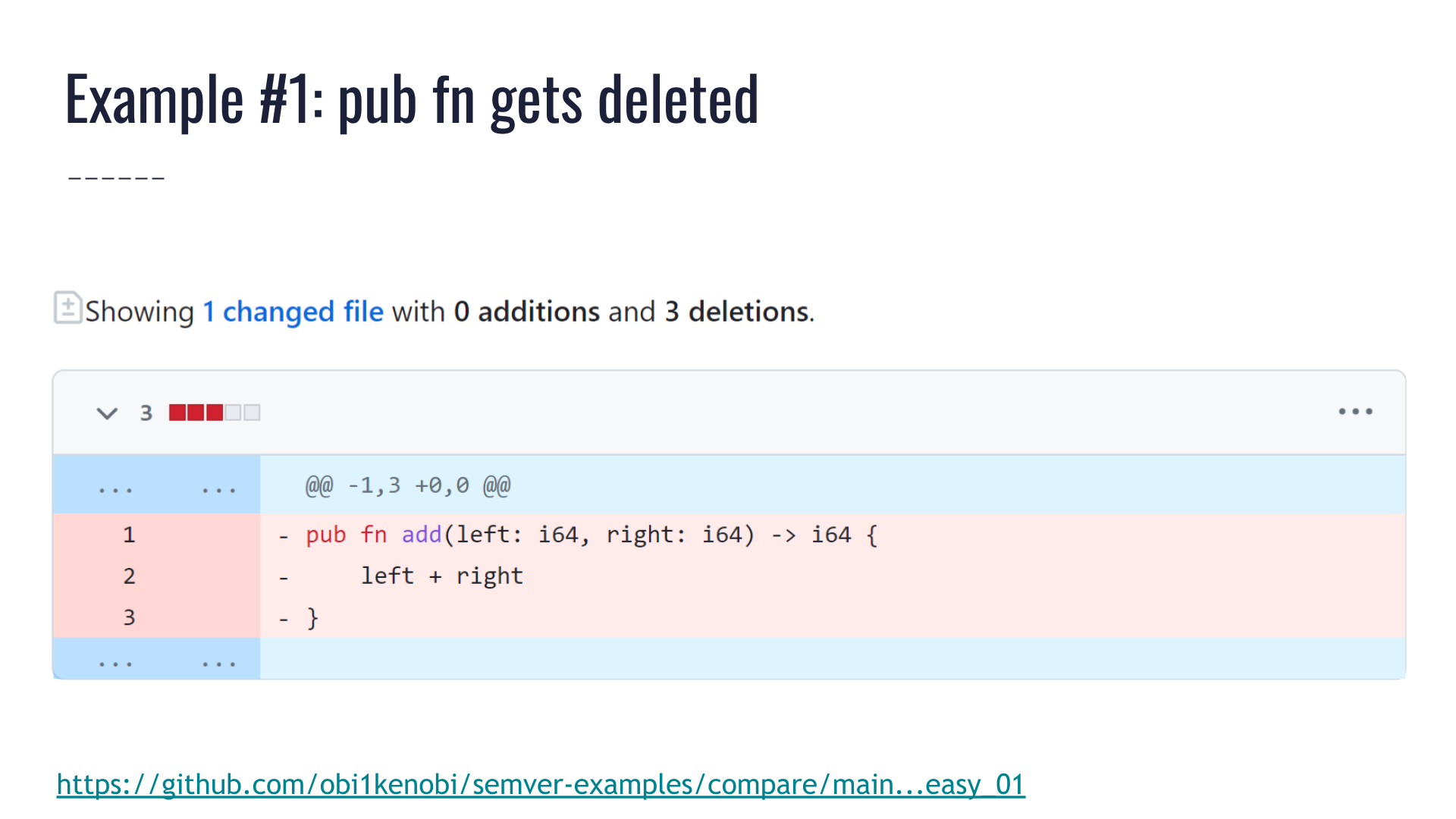
Say a crate exposes a public function called add, and a pull request deletes that function.
This is obviously a breaking change, and cargo-semver-checks will point that out:

This is great! But maybe we didn't need a tool here — we would have caught this "by eye" too.
Not so fast!
Deletions of public items are not always a major breaking change!

There are at least two ways to delete a public function without a breaking change.
![Two blocks of code. The first shows a public function defined inside a private module — even though it's public, the function cannot be imported from outside its crate. Deleting it is not a breaking change. The second block shows a public module marked `#[doc(hidden)]`, and a public function defined inside it. Even though this function can be imported, it is not considered public API since it would have to be imported from a `#[doc(hidden)]` module. Deleting it is not a SemVer major change either.](https://predr.ag/processed_images/slide-27.48b6746eee337fe2.png)
One way is if the public function is inside a private module. The function isn't reachable — there's no way to import it. Nothing outside its crate could have used it, so deleting it can't break anyone.
The other way is trickier: it involves the #[doc(hidden)] attribute. This is a way to mark a piece of your crate's public surface area as not being public API.
#[doc(hidden)] is most often used by crates that define macros: macro-generated code lives in the downstream crate, so it can only access public items from the crate that defined the macro. But those publicly-visible implementation details are intended to be used only by the macro — they are not public API on their own. That's why they are marked #[doc(hidden)].
If our public function is #[doc(hidden)], or if it must be imported from a #[doc(hidden)] module, then it isn't public API and its deletion is not a major breaking change.
So is it safe to say "oh, this function is defined inside a #[doc(hidden)] module so it must not be public API?"
Surprisingly, no!
![Another block of code. It shows a public module marked `#[doc(hidden)]` containing a public function. A line of code adjacent to the module performs a re-export (`pub use`) of the public function, making it possible for other crates to import the function without touching any non-public APIs. Neither the function nor its re-export are themselves `#[doc(hidden)]`, so this function is public API under the path `this_crate::example`. Its deletion would be a major breaking change.](https://predr.ag/processed_images/slide-28.4dc485eccd9eb3cd.png)
Here we have a public module that's #[doc(hidden)] and a public function inside it.
But that public function is public API, because it's re-exported without #[doc(hidden)]. Users of this crate could have imported it that way without using any #[doc(hidden)] items.
Who knew that a simple question like "is it breaking if I delete a public function" could have so many edge cases! [Sidenote: There even more edge cases than I've mentioned here. Properly handling #[doc(hidden)] in cargo-semver-checks was hard! For example, #[doc(hidden)] could be applied to enum variants, or even individual fields within a struct or enum variant. In that case, the struct or enum itself is public API but some of its components are not. Another example is that maintainers often apply #[doc(hidden)] on deprecated items in order to hide them from documentation such as docs.rs — but deprecating an item is not a major breaking change, and in this case #[doc(hidden)] does not exempt that item from the public API. For even more edge cases, check out my post on how we check SemVer in the presence of hidden items.]
So far, we've seen that:
- Deleting a public function might not be breaking.
- Adding a public function is definitely breaking, but not SemVer-major.
This might seem completely backwards, but it's accurate! SemVer is hard.
We found hundreds of SemVer violations here while scanning the top 1000 Rust crates.
cargo-semver-checks handles all these cases correctly. [Sidenote: As of this writing, there's a rare edge case that the tool sometimes doesn't handle correctly: re-exporting an item defined in another crate. All cross-crate analysis is currently blocked on upstream functionality. Thankfully, this is not something crates often do, so at the moment this is an occasional annoyance than a show-stopping bug.]
Computers easily outperform humans here.
Example: Can adding fields to a struct be a breaking change?
Jump to this chapter in the video.

Here we have a pull request that is adding a new field to an existing public struct Foo.
The author of this pull request was quite careful! They noticed the struct has a constructor Foo::new(), and they made sure the new field doesn't cause a change in the constructor. Instead, they initialized the new field to a default value.
This seems entirely reasonable! None of the methods are broken. All the prior public fields still work. This is a purely additive change. It's a solid pull request, merge it!

Oops! 💥
A breaking change just slipped past us.
![Annotations over the code in the aforementioned pull request. They point out that the `pub struct Foo` was not marked `#[non_exhaustive]`, and that all its prior fields were public, therefore downstream users were allowed to construct `Foo` values with struct literal notation: `Foo { first: 0, second: false }` Such uses are broken by this pull request, since they don't specify any value for the new field named `third`.](https://predr.ag/processed_images/slide-31.605ea25a0854e542.png)
The issue is that this struct is not marked #[non_exhaustive], and all of its prior fields were public. This means downstream crates could have constructed the struct directly via a struct literal, by specifying values for all its fields instead of calling Foo::new().
Adding a new field will break that code since it doesn't specify what value the new field should have — that's a compile error.
This is not at all obvious! No human is perfect, and this could easily slip through code review. We found breakage like this hundreds of times in our SemVer study of the top 1000 Rust crates.

cargo-semver-checks will catch this issue 100% of the time. [Sidenote: In fact, cargo-semver-checks even differentiates between two ways to cause breakage here: adding a new public field will require specifying the field in struct literals, while adding a new private field will disallow using struct literals altogether.]
[Sidenote: Anecdotally, many Rustaceans I've spoken to were surprised to learn that structs could be marked non-exhaustive at all! If you use cargo-semver-checks, you don't need to be an expert in Rust — the necessary expertise is distilled into the tool and is a few keystrokes away.]
Adding fields to a struct can sometimes be a breaking change; terms and conditions apply. If you use cargo-semver-checks, you don't have to remember this fact — let alone its terms and conditions.
Example: Can modifying a private item cause a breaking change?
Jump to this chapter in the video.

Here we have a private struct Foo, and we're just changing some internal implementation details. It used to hold a &'static str, and we now want to support non-'static strings.
The struct is Clone, so to keep cloning cheap we're going to use a reference-counted string type: Rc<str>.
We changed private implementation details of a private type. We didn't touch any public API. Surely we couldn't have broken any public API? If I didn't touch it, I didn't break it!

Darn! 💥
But ... how?! What broke?
Run cargo semver-checks and let's see what it says.

How strange! The pull request changed the private struct Foo, but cargo-semver-checks complains about a public type Bar.
Our pull request didn't change any type Bar!
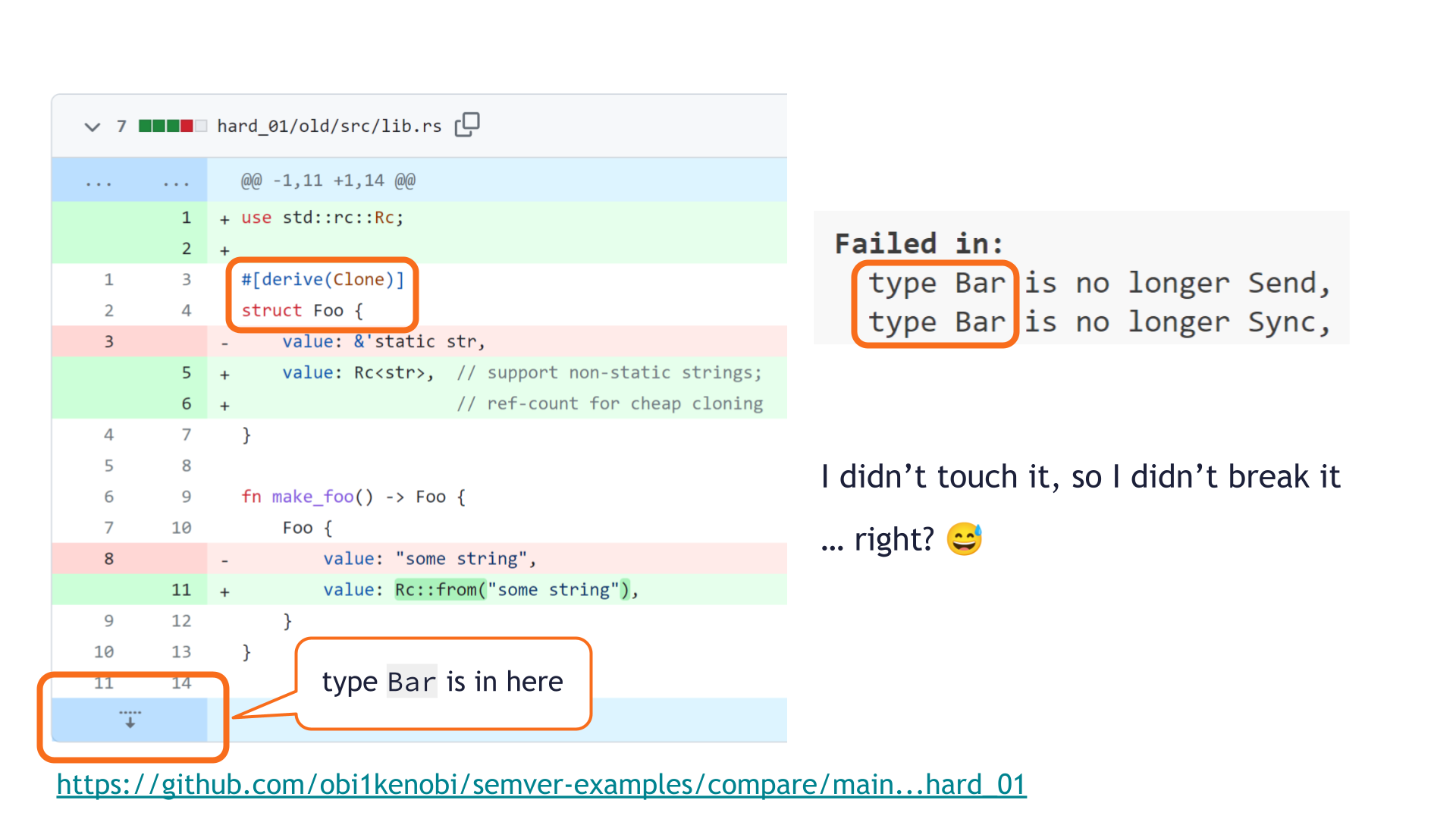
Bar's definition isn't even shown in the pull request review screen, so surely it's irrelevant here? Maybe this is a false-positive in cargo-semver-checks?
Unfortunately, no such luck. We did cause a breaking change, and since the broken API was never shown in the UI, we were never likely to spot it during code review.
Here's what happened.

pub struct Bar exists elsewhere in our library, and contains a Foo value.
As a public struct, the traits it implements are public API as well.
Rust has a small group of traits called auto traits, which are automatically implemented for types whenever possible. Send and Sync are the most commonly used auto traits — this is how the Rustonomicon describes them: [Sidenote: We've previously discussed auto traits and the SemVer breakage they might cause in this post.]
SendandSyncare also automatically derived traits. This means that, unlike every other trait, if a type is composed entirely ofSendorSynctypes, then it isSendorSync. Almost all primitives areSendandSync, and as a consequence pretty much all types you'll ever interact with areSendandSync. Major exceptions include: [...]Rcisn'tSendorSync(because the refcount is shared and unsynchronized).
The struct Foo's original &'static str field implemented both Send and Sync, whereas Rc<str> implements neither. That change makes struct Foo no longer implement Send or Sync, so pub struct Bar is no longer Send nor Sync either.
This change in the traits of a public API type is breaking!

Our downstream users might have been using Bar in a use case that relies on parallelism. Some Bar may have been shared across threads, or passed between threads.
Their code is now broken. Instead of working code, they will see an error like the above.
We saw hundreds of accidental breaking changes like this in our SemVer study of the top 1000 Rust crates. But this wasn't a skill issue!
Not only do the maintainers of those crates know about auto traits — they've certainly been on the receiving end of breakage caused by auto traits. They have the skills — but they weren't set up for success here.
This is a case where private code can break public API via "spooky action at a distance," where the affected public API is never displayed during code review. None of us stand a chance in such circumstances — without automated help, shipping breakage like this is a question of time.
cargo-semver-checks uses the Rust compiler's own machinery to determine the auto traits each type implements.
It will catch this issue 100% of the time.
cargo-semver-checks lints are database queries in disguise
Jump to this chapter in the video.
Now that you've seen some of the issues cargo-semver-checks can flag, let's talk about how it works and why you should trust what it can find.
Let's come back to the earlier example of determining whether deleting a public function is a major breaking change.
![Checklist of conditions that must be true if a function's removal is a major breaking change: previously, the function must have been public; another crate could have imported and used it; that import did not rely on any `#[doc(hidden)]` items, and now that same import name no longer satisfies the previous conditions. Finding all such functions sounds like a database query...](https://predr.ag/processed_images/slide-39.fd287e07018b1bf0.png)
We have a major breaking change only if all of those conditions are true.
It's breaking because we've found a case where an import of a public API component from an older version no longer works in the newer version. Either the function is no longer publicly available, or it can't be imported anymore, or it's #[doc(hidden)] meaning it isn't public API anymore. In any case, that's a major breaking change.
Say we want to find all such functions that have caused a breaking change.
One could read the rule on this slide as "select functions where X and Y and Z ..."
That sounds like a database query!
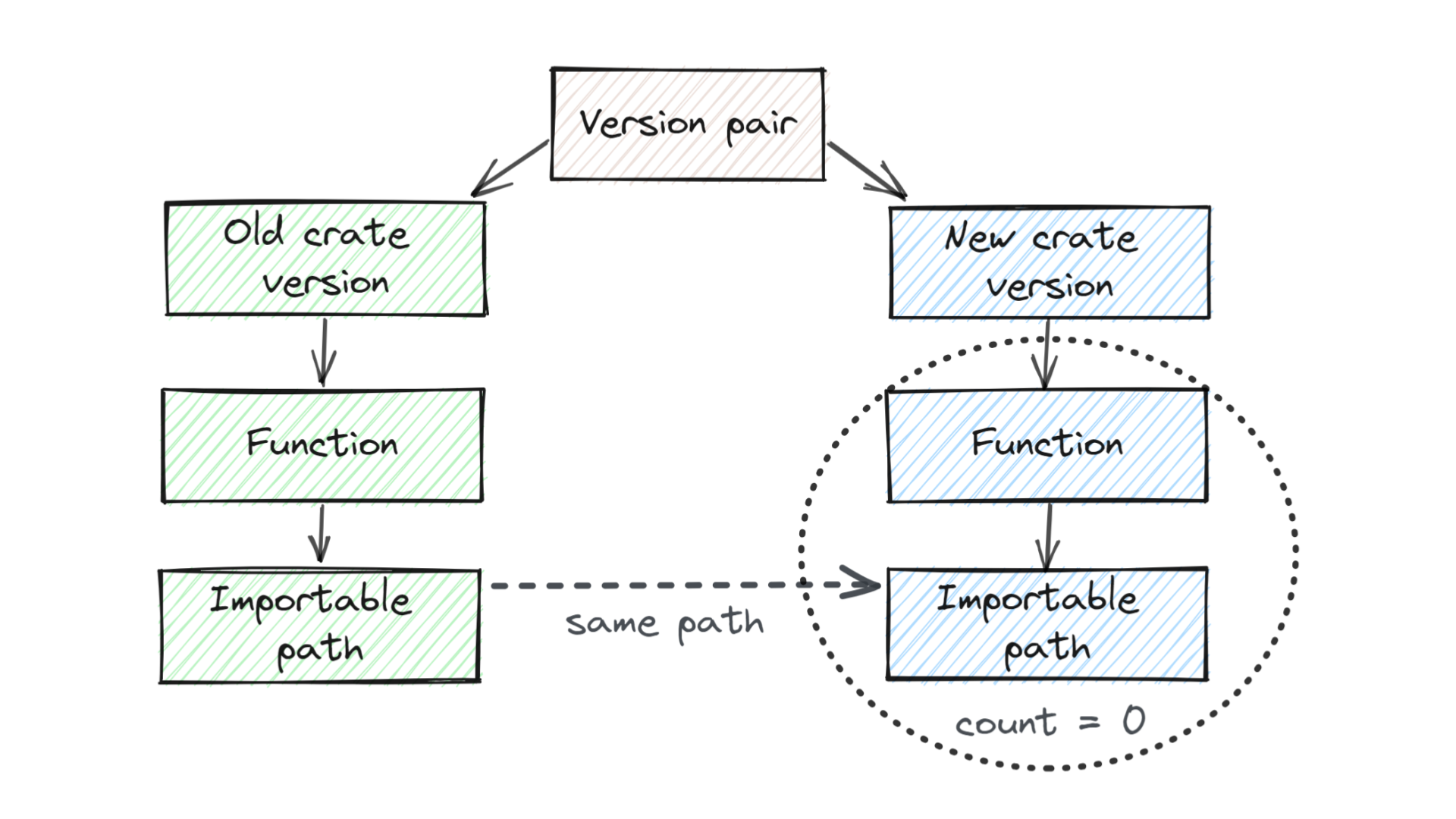
Structurally, it looks like this.
We are comparing a pair of versions: old version on the left, new one on the right.
We're looking for public functions that are importable and public API on the left. We're going to try to match them to public functions in the new version, at the same import path as the function that we were just looking at.
If we can't find any such matching function in the new version of the crate (i.e. if "we count zero matching functions") then we've found a breaking change: we've found a specific function that previously could be imported and used, but now it can't be imported and used anymore.
This is exactly what cargo-semver-checks runs under the hood.

We aren't going to dig into the query syntax here.
But at a glance, we can see the query does the same thing we described in plain language earlier:
- It looks at public functions in the old version of the crate.
- It ensures that some public API path could be used to import them.
- In the new version, it attempts to match each function to a corresponding public function at the same public API import path.
- It sets the
count = 0condition on the number of such matching functions in the new crate. - Along the way, it outputs some of the values that will be handy when constructing our error message: we want to know which function was the problem, at which path, etc.
We just wrote down the SemVer rule in human language, we translated it into a database query, and we called it a day. The business logic of SemVer can be entirely ignorant of how we run the query, or how we obtain the information on the public API.
This is pretty nice!
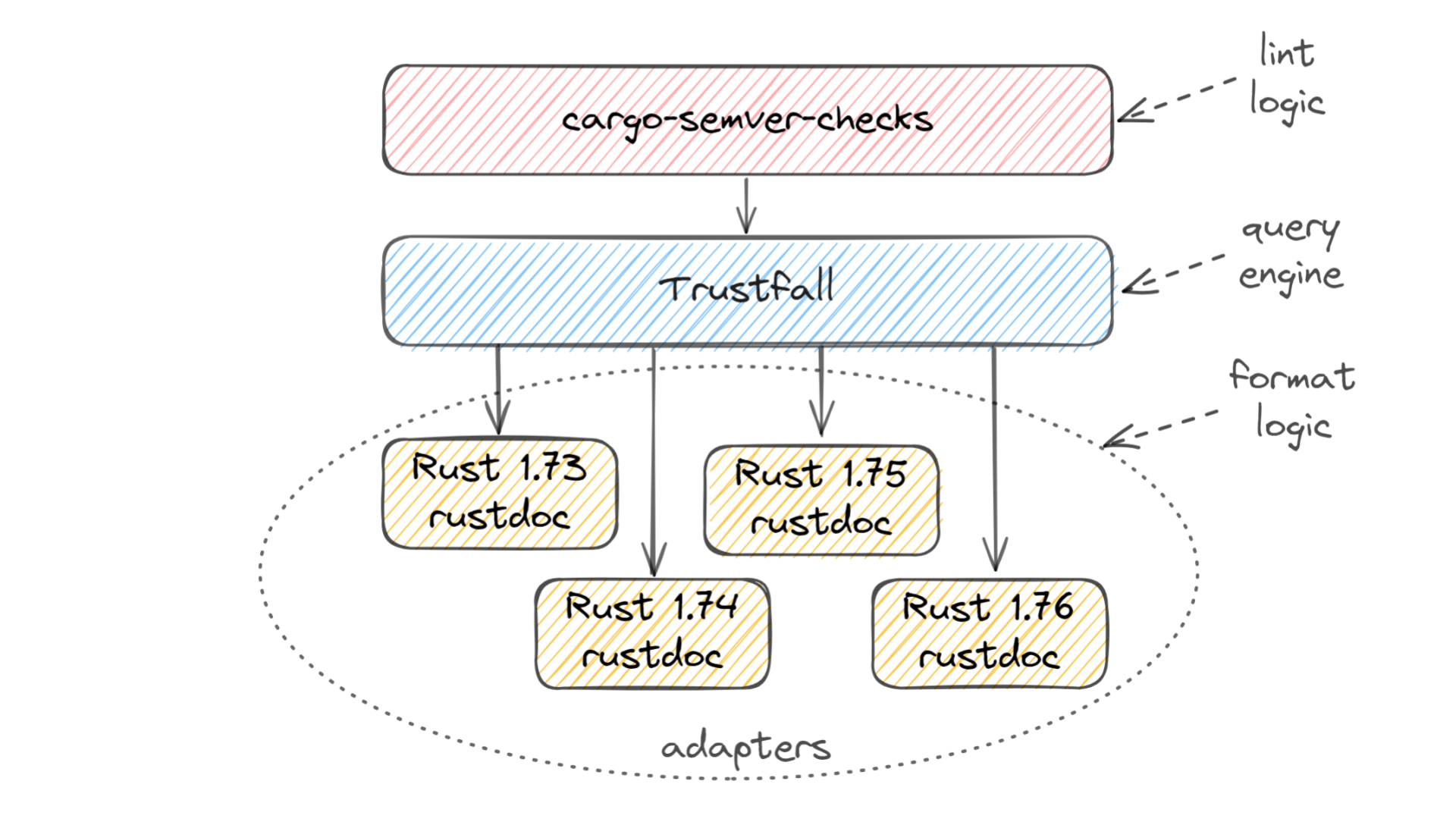
Here's how that works under the hood.
cargo-semver-checks on top is where all the lints are stored. Each lint consists of a query, some string templating for forming the user-facing diagnostic message, and some metadata such as a reference link where the user can learn more about the type of breaking change that was detected. This layer doesn't know where the data is coming from, or what format it's in.
At the bottom is all the logic related to the incoming data format. We use Rust's built-in rustdoc tool to generate JSON describing the API of each version of the crate being checked. This JSON format is not stable — it changes often — so we have different code paths in order to support multiple formats.
In the middle lies the Trustfall query engine. cargo-semver-checks runs its lints as Trustfall queries, and Trustfall in turn uses small pieces of code called adapters that understand the nuances of each rustdoc JSON format we support.
This separation between the SemVer logic and the underlying data format is the key to cargo-semver-checks success:
- Support for multiple stable Rust versions. Unlike many other tools that use rustdoc JSON,
cargo-semver-checksdoes not require using a specificnightlyRust version. Any reasonably recent Rust stable release would do, as would most pre-releases. - Lints are easy to write. They query a high-level schema which talks about Rust structs and fields, enums and variants, functions and their arguments — the familiar concepts of the Rust language, instead of implementation details of a specific JSON format. No prior knowledge of static analysis or query optimization is required to write lints or ensure they run quickly! [Sidenote: For a deeper dive into how the query optimizations work, check out my "Speeding up Rust semver-checking by over 2000x" post]
- Maintenance is easy. When the JSON format gets changed, we do not need to change any lints. There are dozens of lints (more are added every week!), so it would be prohibitive if we had to update them on every format change. Instead, we make a new adapter copy and tweak it as needed to accommodate the changes in the format, and everything just works. [Sidenote:
cargo-semver-checksisn't the first SemVer linter for Rust! Prior attempts at linting SemVer were either abandoned due to excessive maintenance burden, or require a specific nightly Rust version to work — or both.]
A peek at Trustfall, an engine for querying everything
Jump to this chapter in the video.

Trustfall is another project I started.
It allows us to represent data as a graph and query any kind of data sources. It is not something that's specific to Rust or rustdoc at all.
Its first iteration was deployed to production in late 2016, [Sidenote: The modern Trustfall query engine is the "from the ground up" Rust rewrite of a Python project called graphql-compiler which my previous employer open-sourced.]
so it's had 7+ years in production use.
It can be used to query any kind of API, database, file format, etc. It can run queries in-place, without needing ETL or any similarly heavyweight process.
Its adapters can be written in Rust, Python, JavaScript, or WASM — or any other language that can have bindings to Rust.
I've given two prior talks related to Trustfall:
- “How to Query (Almost) Everything” — HYTRADBOI 2022
- “How Database Tricks Sped up Rust Linting Over 2000x” — P99 CONF 2023
You can try Trustfall in our playgrounds over rustdoc JSON or over the HackerNews REST APIs.
The rustdoc JSON playground uses the same exact code that powers cargo-semver-checks, and lets you find out interesting things about a variety of Rust crates — such as which Rust or clippy lints they've disabled and where.
The HackerNews playground lets you check, for example, which Twitter or GitHub users comment on stories about OpenAI.
In both of these cases, the Trustfall query engine is compiled to WASM and runs entirely in your browser. So feel free to run any query you like, no matter how expensive — it's your CPU and your bandwidth that's used to compute it 😁
Conclusion: Solving maintainability led to a tool that users love
Jump to this chapter in the video.

There are hundreds of ways to accidentally break semantic versioning rules in Rust.
That problem is hard enough to solve by itself, without also worrying about JSON format changes breaking your implementation. [Sidenote: We want to have a working SemVer linter, and we also want the rustdoc maintainers to be able to freely change the JSON format if that has benefits across the Rust community! The Rust language is still growing — for example, Rust 1.75 added async fn in traits — and rustdoc JSON has to be able to express these new concepts. The rustdoc team has a hard enough job as it is, and we don't want to tie their hands further by restricting which kinds of format changes may happen when.]
Trustfall makes cargo-semver-checks possible.
It lets us prevent an ever-growing number of accidental breaking changes, while also making lint-writing approachable to people of all backgrounds. Many lints are first-time contributions from our community members who had no prior experience writing linters!
Most importantly, our users love us. Everyone prefers to find out about accidentally-breaking changes before they get pushed to production, instead of finding out when someone opens an issue like "hey, you broke my project."

Hopefully by this point I've convinced you that:
- Semantic versioning is valuable, but it's impossible without automated help.
cargo-semver-checksis a solution to this problem that has lots of happy users.
If you'd like to help, you can contribute code, lints, and funding to cargo-semver-checks.
There are dozens more breaking changes that we need to write lints for, and lots of other not-yet-built functionality as well. So please consider becoming a GitHub Sponsor — either personally or via your company.
Finally, for the sake of everyone in the Rust community, please try to avoid accidental breaking changes. Nobody will blame you for them, but it's a lot better for everyone if you find them before you ship the new release.
cargo update should be fearless — cargo-semver-checks is here to help!