In 2022, I gave a talk at a virtual conference with an unforgettable name: HYTRADBOI, which stands for "Have You Tried Rubbing a Database On It?" Its goal was to discuss unconventional uses of database-like technology, and featured many excellent talks.
My talk "How to Query (Almost) Everything" received copious praise. It describes the Trustfall query engine's architecture, and includes real-world examples of how my (now-former) employer relies on it to statically catch and prevent cross-domain bugs across a monorepo with hundreds of services and shared libraries. For example:
- Catch Python services that specify one Python version in their
pyproject.tomlmanifest, and a different (incompatible) Python version in their deployment Dockerfile. - Catch Python libraries that specify type hints, but whose CI configuration has disabled
mypytype-checking, meaning that the included type hints may be incorrect.
The talk's contents are still relevant today, with Trustfall now powering tools like cargo-semver-checks. And as far as I know, my former coworkers are still happily using everything described in the talk! [Sidenote: As I am no longer employed at that company, everything in this post is written in a personal capacity, and may not represent the past or present opinions of my prior employer. Also, don't read too much into my departure — I was there for 7+ years, left on good terms, and many of my friends still work there.]
I hope you enjoy!
You can watch the talk video on the conference site, on YouTube, or embedded below. Read on for an annotated version of the talk, [Sidenote: I believe Simon Willison coined the term "annotated talk", and described it on his blog. I like this idea, and I'm broadly aiming to follow the same approach.] covering the same ideas in written form.
Outline
- Problem: Querying non-database data is hard
- Agenda: Querying everything is valuable, and easier than it looks
- Never debug the same problem twice
- Basics of querying everything
- Demo: What GitHub Actions are used in projects popular on HackerNews?
- How Trustfall executes queries
- Why plugging in a new dataset is easy
- We've only scratched the surface!
Problem: Querying non-database data is hard
Jump to this chapter in the video.
We're in a funny situation these days: queries that are trivial in a SQL database are painfully difficult over any other data source.
Let me give you an example.
What GitHub Actions are used in projects popular on HackerNews?
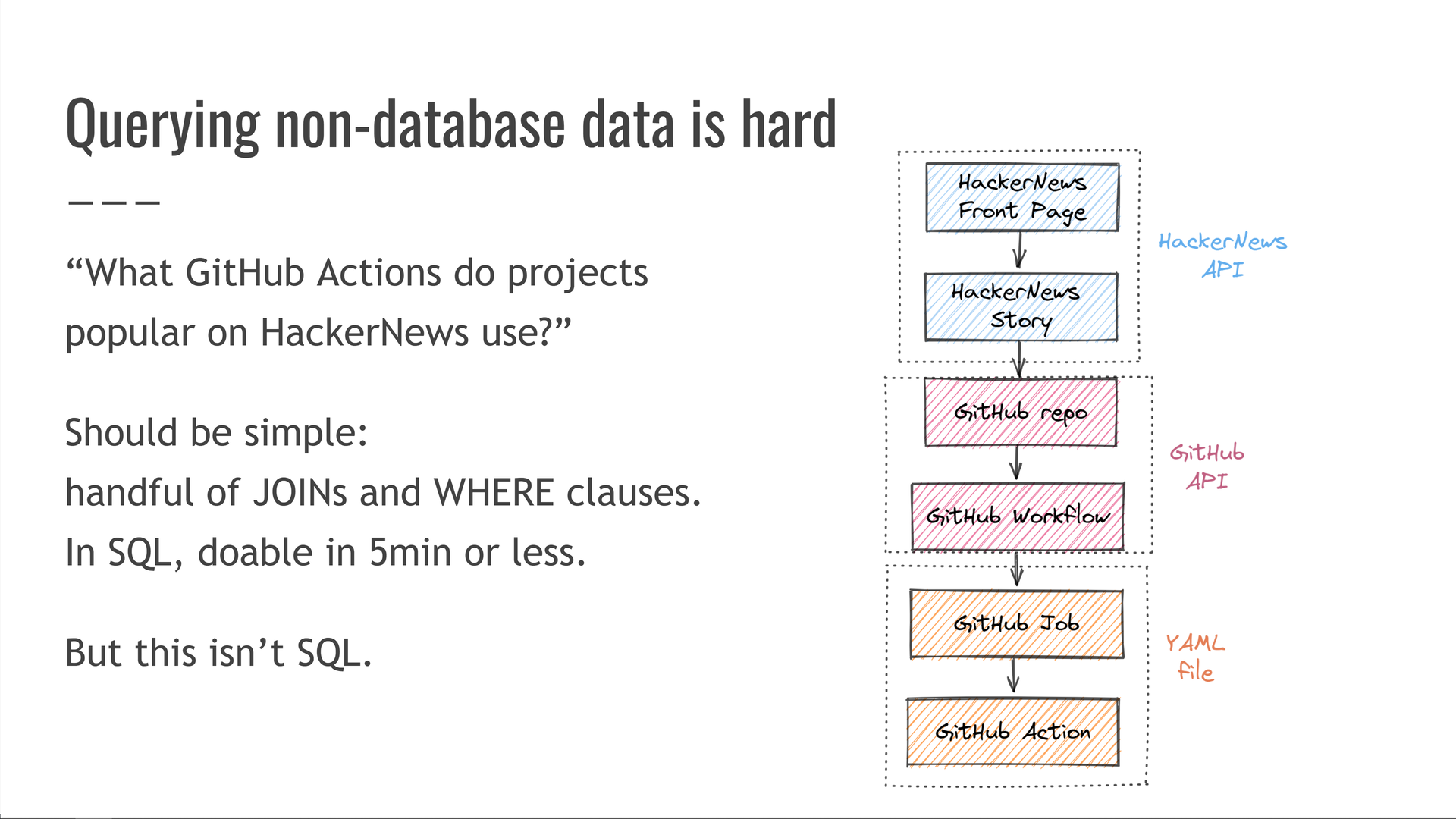
In principle, this should be simple! If we had this data in a SQL database, this query would just be a handful of JOIN and WHERE clauses — we should be able to write it in just a couple of minutes.
But we don't have this data in SQL. Instead, we have to cross-link the HackerNews API, the GitHub API, and a the custom GitHub Actions YAML file format.
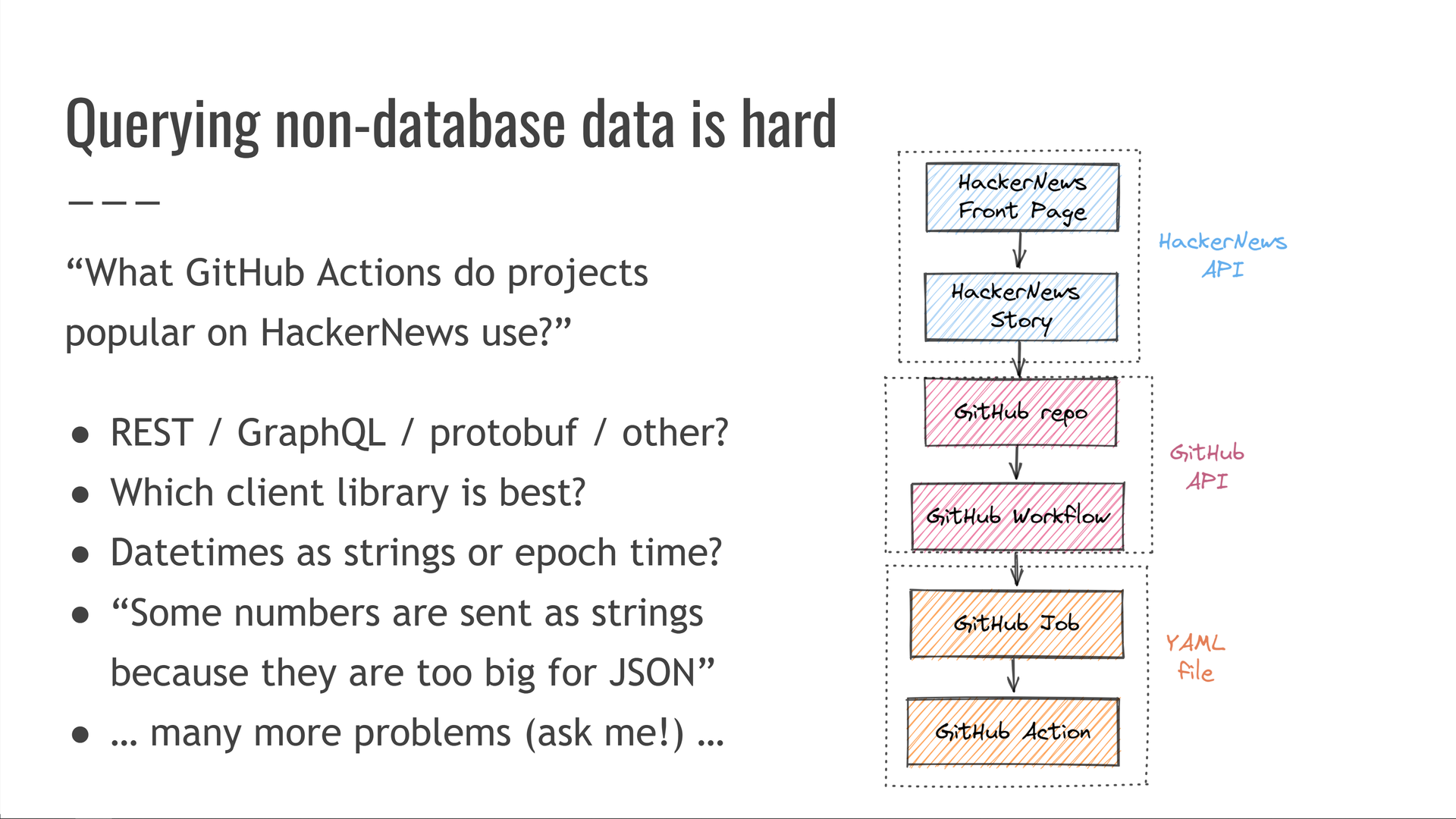
We then have to worry about things like:
- How is the API structured? Is it REST / GraphQL / protobuf / something else?
- What client library is best for my programming language?
- Are datetimes represented as RFC 3339 strings or seconds since epoch?
- Are numbers sometimes sent as strings because they might be too big for the data format, like 64-bit integers in JSON?
And we haven't even gotten to actually running the query yet!
The end result is that this query becomes so annoyingly difficult that it might just not be worth doing it at all.
Agenda: Querying everything is valuable, and easier than it looks
Jump to this chapter in the video.
In this talk, I want to convince you of two things.

First, that querying almost everything is super valuable. For this, I'll show you a case study with my former [Sidenote: I left Kensho at the end of 2022, after joining it as a tiny startup and seeing it grow over 7 years. But I gave this talk in April 2022, at which point Kensho was still my employer.] employer, Kensho.
Second, that querying almost everything is really easy! For that, I'll show you a demo of the query we were just talking about.
Never debug the same problem twice
Jump to this chapter in the video.
At Kensho, we found that debugging the same problem over and over again is a huge waste of time. We decided to solve that.

Debugging the same problem more than once is the byproduct of many engineering and social challenges we had to overcome.

Systems fail in complicated ways, people forget things, etc. It isn't obvious how to use "team A debugged something" to prevent team B from ever having to debug the same thing in the future.
This requires having perfect institutional memory across the entire company, forever.

Our solution is to query for reoccurrences of known problems, then prevent them.
We have queries looking for about 40 known problems. [Sidenote: This was the correct number at the time I gave this talk. By the time I left Kensho around 6 months later, that number had grown substantially.] We also keep adding one to two new queries per week.
Each time someone opens a pull request, we scan their code with all of these 40 queries. This takes about ~0.3s, even though we haven't done much optimization work to bring this number down further.

That third of a second in extra CI time has saved countless hours from being wasted on debugging.
Even more importantly, detecting problems earlier frees up infra and SRE resources! This is a bit subtle, so bear with me: say you have a dozen teams deploying services to production. Then one of those services suffers an prod incident — who bears the cost of resolving it? The team that owns the service, but also the infra and SRE teams!
Now extend this over the course of months: different services suffer incidents, but infra and SRE bear a cost each time while the rest of the burden is spread across different teams.
This tool reduces the number of prod incidents by catching buggy code earlier, and preventing it from being merged and deployed at all. While each service-owning team is a bit faster and happier, infra and SRE teams experience a massive positive effect: they get paged and interrupted less often, they have more cycles to ship further improvements, and they are happier too! This sets up a glorious positive feedback loop: infra and SRE have more cycles, leading to more infra upgrades and more checks, which in turn decreases incidents further and leads to even more cycles for everyone!
We also found that everyone can be successful at writing queries — our engineers, product managers, and analysts all had success with it as well.
The net result: we ship bigger things, faster. Since nobody likes debugging, everyone is happier too! [Sidenote: Another observation: this system changed our collective viewpoint from, loosely speaking, "incidents happen" to "wait, how could we have prevented that?" If preventing problems feels expensive, one wouldn't try to prevent them and instead learns to live with them. But when prevention suddenly became orders of magnitude cheaper, we found ourselves writing new checks after every incident or near-miss.]
Example: Python version mismatch in pyproject.toml vs Dockerfile
Jump to this chapter in the video.
Let me give you an example of what these queries look like.
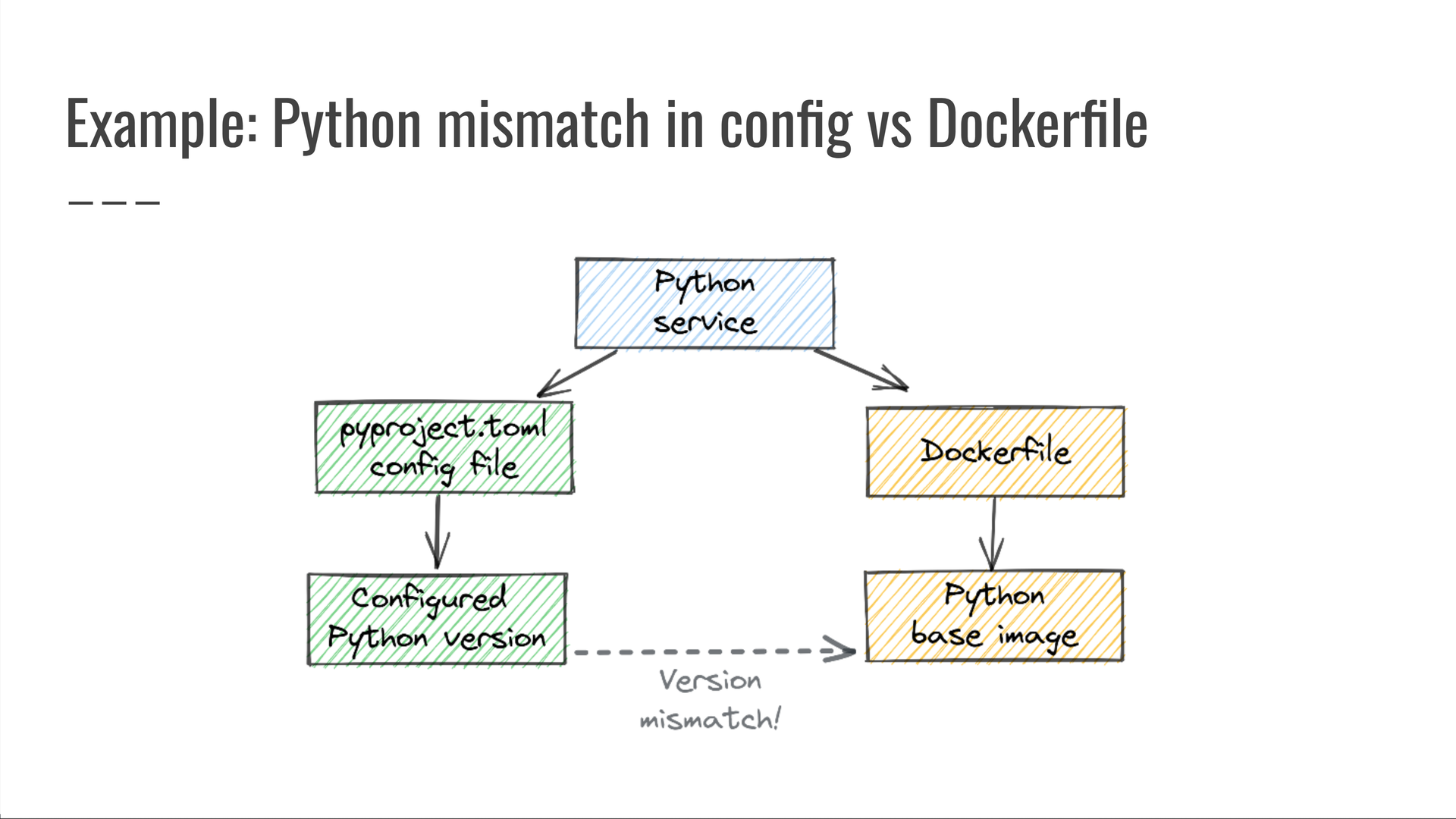
At one point we had to debug a situation where a Python service was deployed with an unexpected version of Python, which didn't match the version its pyproject.toml file specified.
To prevent such incidents going forward, we wrote the following query: "Look for Python services whose pyproject.toml config file specifies one Python version, but the Dockerfile used to deploy that service specifies a different Python version." Any results of running this query were clear bugs, which were promptly fixed and prevented from ever coming back.
This is a query across three data sources:
- our monorepo's service definitions files, written in JSON;
- the TOML-based
pyproject.tomlproject configuration file, and - the
Dockerfilethat governs how the service is deployed.
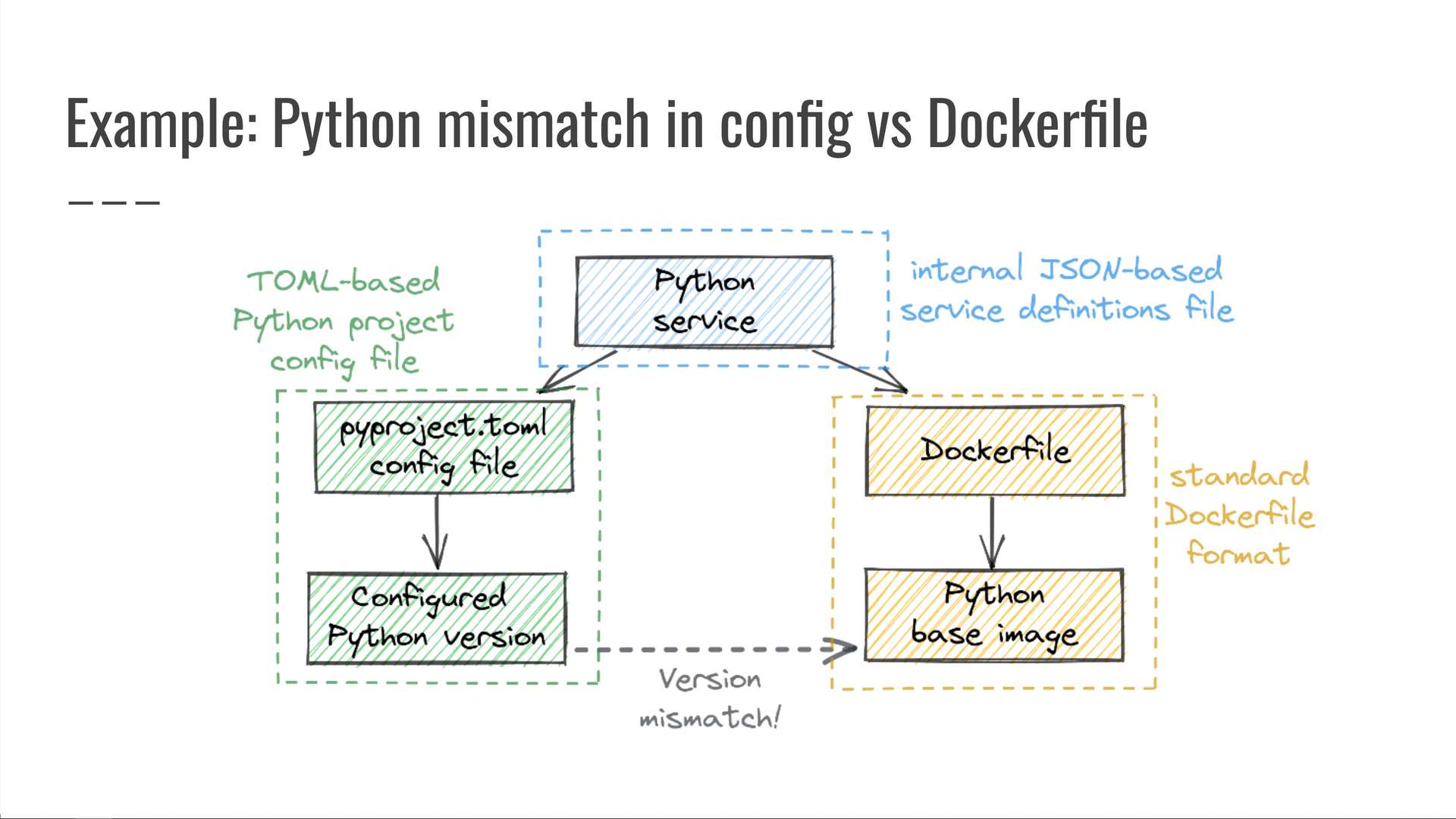
It's impossible to catch this issue without looking at all three data sources at once! By themselves, they all seem fine — a valid service definition, a normal pyproject.toml file, and a reasonable Dockerfile.
The issue is not with any of them individually.
The issue is that they won't work together. Only a cross-domain query can spot that.
Example: Python type hints that are never checked
Jump to this chapter in the video.
Here's another example:
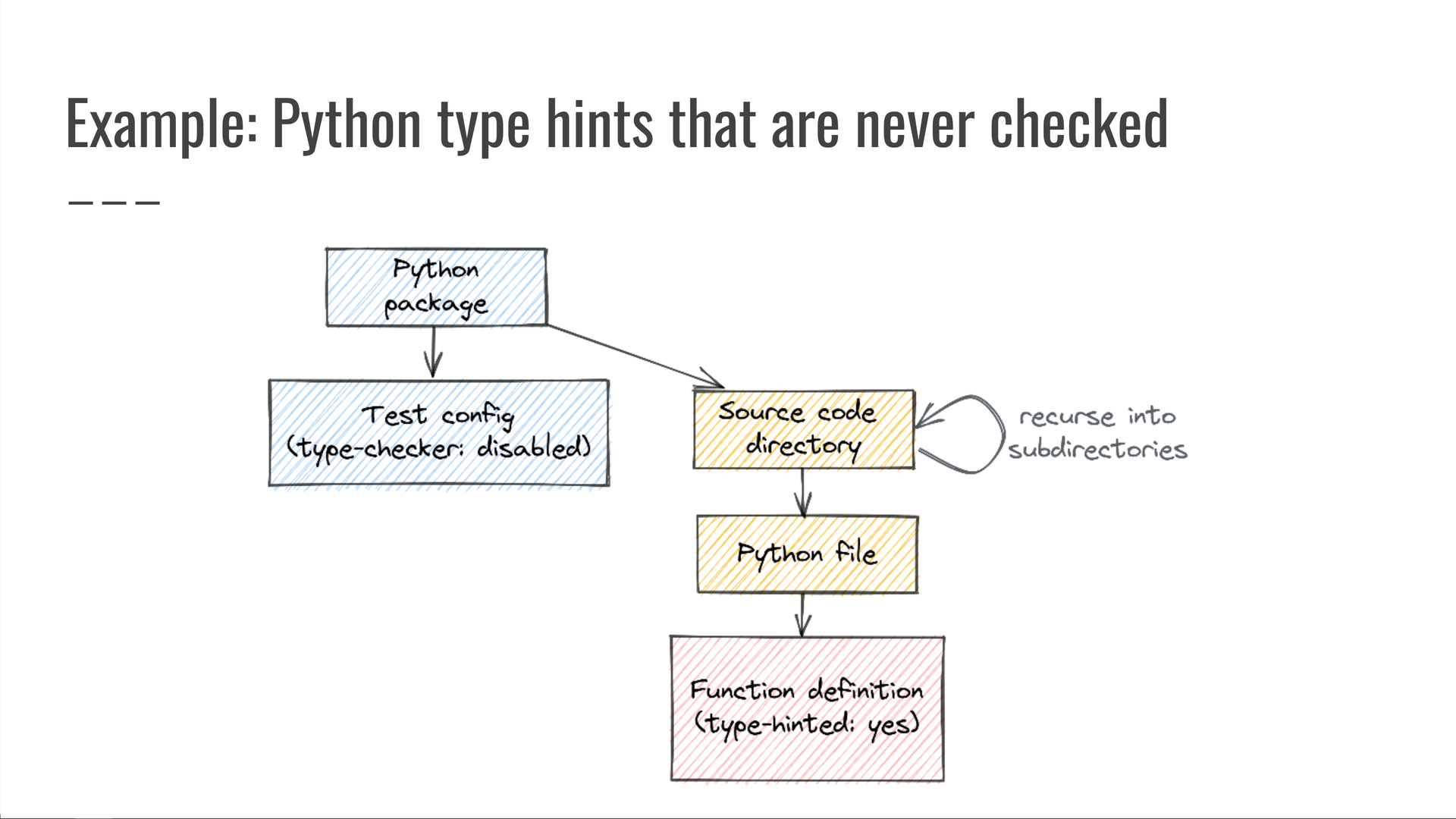
At one point we had to debug an internal Python package that had incorrect type hints, because the package's CI configuration skipped mypy type-checking meaning that the type hints were never checked at all.
We then wrote the following query: "Look for Python packages whose test configuration says to not run type-checking, but whose source code directory (or any of its subdirectories) includes at least one Python file containing any code that specifies a type hint." Since those type hints are specified in the source code but are never checked, they might be wrong — so such code should not be allowed.
Any results produced by this query were clearly concerning, and we worked with the affected code owners to resolve them while also preventing this bug category from ever reoccurring.
Once again, this is a query across multiple data sources:
- our monorepo's Python package definition files;
- our git source control and file system data for the directory and file traversals, and
- the parsed syntax trees of Python source code files, where we look for Python item definitions that include type hints.
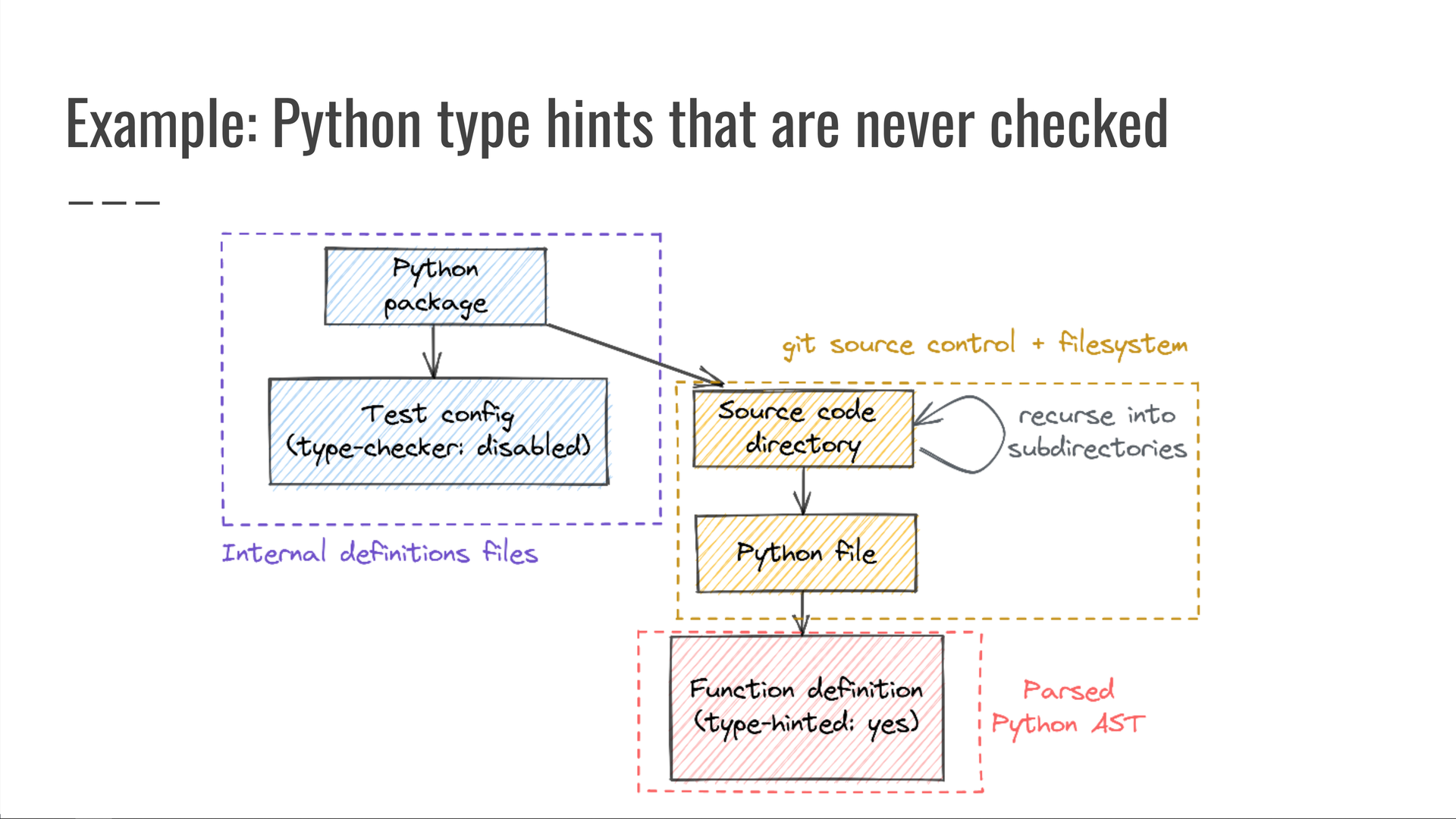
Viewed individually, each of those components seemed fine.
The issue was only detectable when considering them as a whole.
Real-world queries across many data sources are easy and practical
Jump to this chapter in the video.
As of the release of this talk in 2022, more than a dozen different data sources were available for querying in Kensho's system. [Sidenote: Once again, note that this is a talk I gave in 2022 while still employed there. I am no longer a Kensho employee, and cannot speak for my former employer.]

We found that adding a new data source is super straightforward, and makes for a great onboarding project for new engineers and interns on the team.
It also had some additional unexpected benefits!

As soon as it became easy to write queries like "which internal Python packages are never used in any service," we discovered and deleted nearly 300,000 lines of unused code across our monorepo! [Sidenote: Most dead code elimination tools can only find dead code within a single unit, like a library or a service. Queries allowed us to write inter-component analysis, and I got quite good at the "dead code elimination via queries" game! By the time I left Kensho about 6 months after giving this talk, I had the second-highest net-negative lines contributed metric: I had deleted more than 200k lines more than I had added. Not bad for 7 years of work!] [Sidenote: Now, you might be wondering: if I was second on the net-negative metric, who took first place? The answer: my manager, who once found and deleted a 600k line JSON file that someone had committed to the monorepo. I had no such silver bullets, so the gap was insurmountable :)]
Basics of querying everything
Jump to this chapter in the video.
Having covered why querying almost everything is useful, let's see how to do it.
First, we need to perceive everything as a graph.

We'll have a schema that describes our dataset in terms of vertices, typed properties on those vertices, and edges between them. We'll also have a type hierarchy between the different vertex types, so we can say that a GitHubRepository vertex is a kind of Webpage.
This is equivalent to the relational (SQL) model. If you're comfortable with SQL, you'll feel right at home here: vertices are tables, properties are columns, edges are foreign keys, etc.
Here's what our "HackerNews meets GitHub" graph looks like:
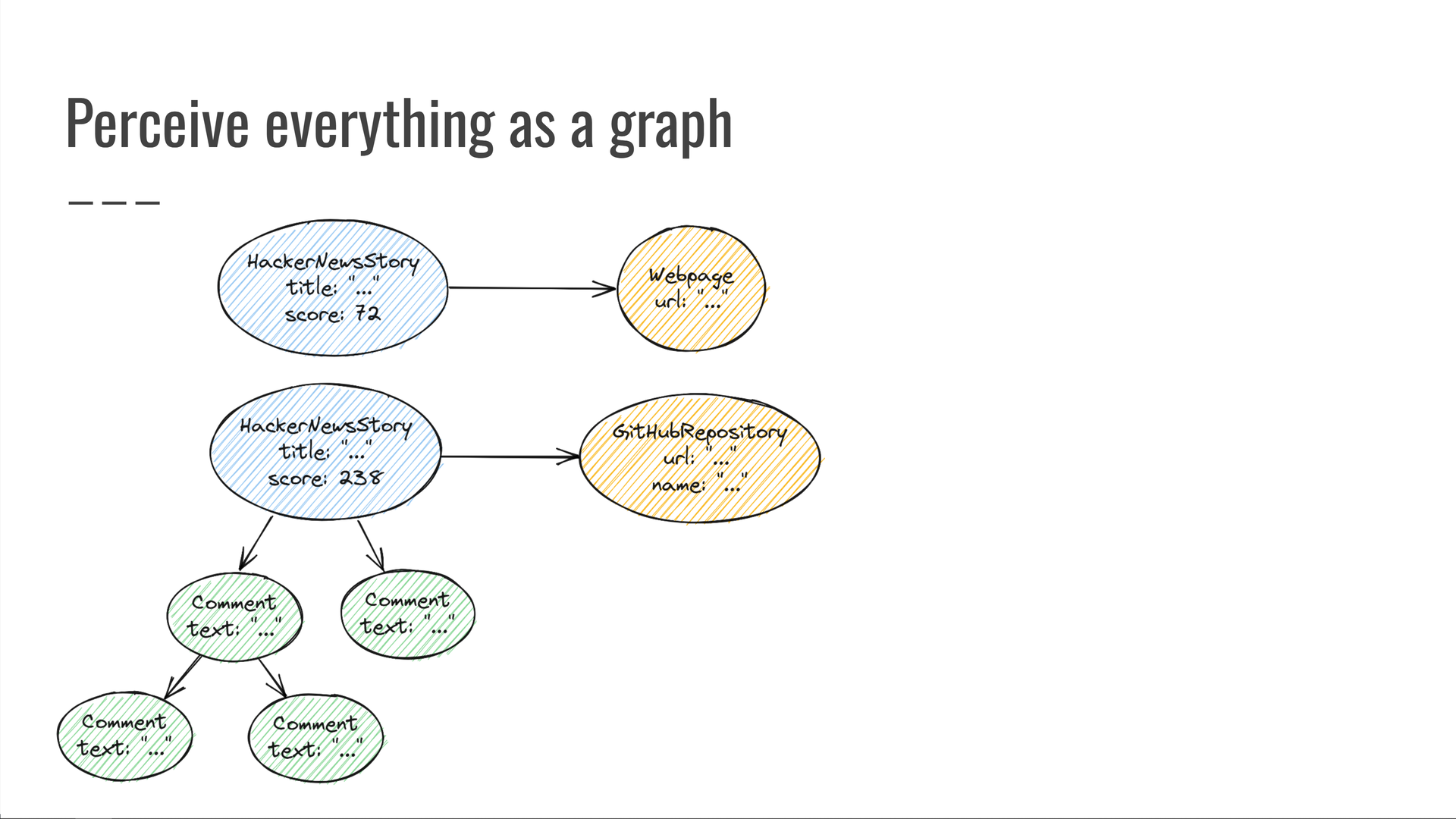
We have some HackerNews stories that have titles and scores. Some of them have comments. The stories point to web pages, some of which are GitHub repositories, and so on.
In order to run a query against this graph, we need to do two things: define a pattern to look for, then select a set of properties to return from the vertices that match our pattern.
For example, let's look for trending HackerNews stories with a score of at least 50 points, which also point to a GitHub repository. For each match, say we want to know the GitHub repository URL and its story's HackerNews score.
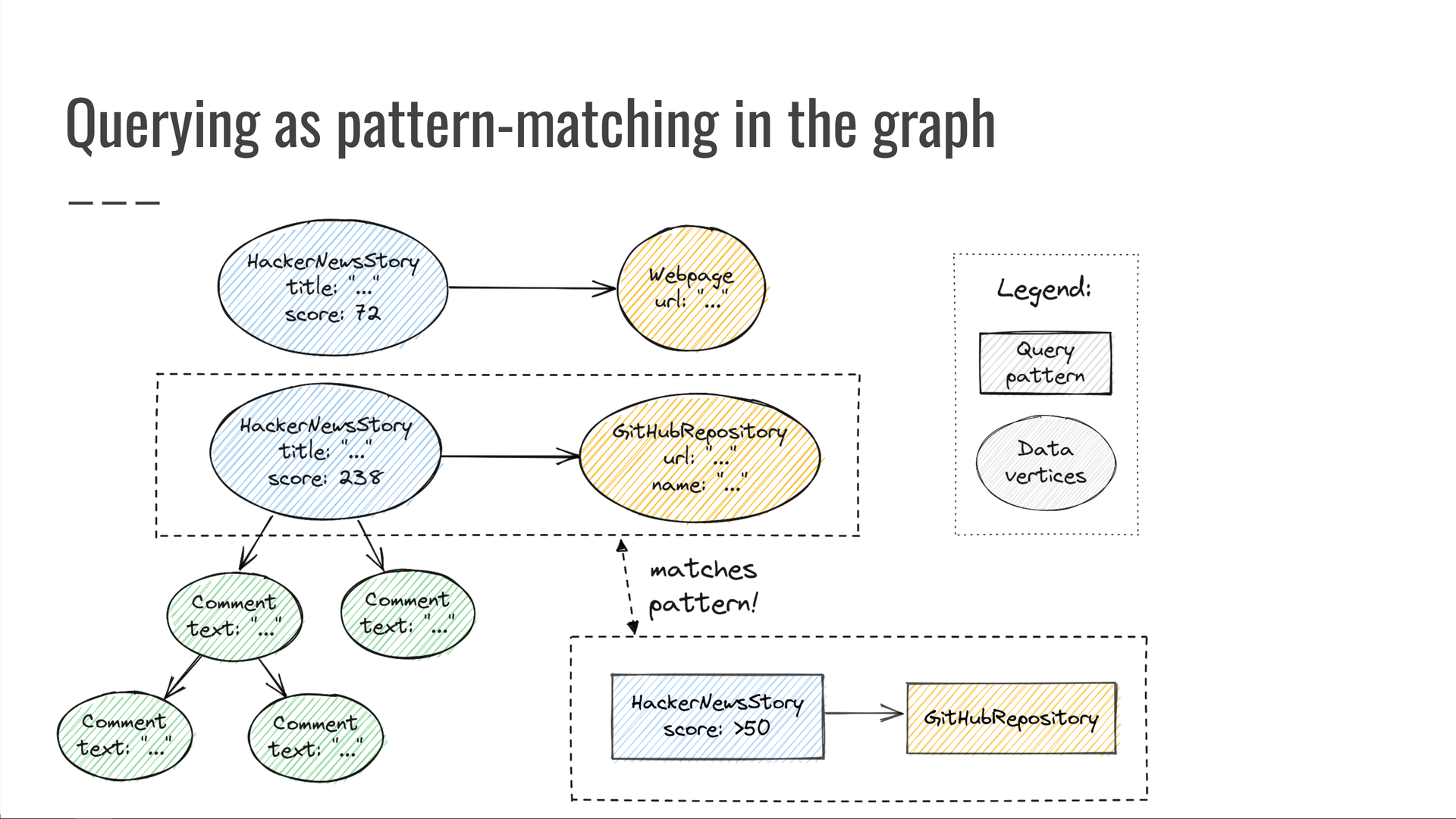
Taking a look at our data graph, we discover some vertices that match our pattern. We then output the values of the properties we were interested in.
Here's what this query looks like in Trustfall's query syntax:
![The query is the following: { HackerNewsTop(max: 30) { ... on HackerNewsStory { score @filter(op: ">", value: ["$min_score"]) @output link { ... on GitHubRepository { url @output } } } } } We provide the query with the value 50 for its "min_score" variable. The "... on HackerNewsStory" clause selects only stories, discarding other kinds of HackerNews items such as job postings. The "@filter" clause applies the "greater than 50 points" predicate on the story's score. The "link" edge on HackerNews stories points to a vertex of type "Webpage", but we are only interested in the Webpage subtype "GitHubRepository" — we select only those by using the "... on GitHubRepository" clause. Since the Trustfall engine is pluggable, its front end can be swapped out to support any alternative query syntax as well.](https://predr.ag/processed_images/slide-24.965a404e7a02d4c1.png)
First, we start with the current top submissions on HackerNews. Then:
- We select only story submissions, discarding other items such as job postings.
- We make sure the score is at least 50 points.
- We ensure that the story's link points to a GitHub repository, and not to just some arbitrary web page.
- We output the score and the repository URL.
Demo: What GitHub Actions are used in projects popular on HackerNews?
Jump to this chapter in the video.
Let's demo Trustfall end-to-end by running the query that seemed so complicated at the start of the talk!

Written in Trustfall syntax, it's a bit more complex than our earlier example — but it's just more of the same operations we already looked at.
We again start with the top submissions on HackerNews, discarding everything that isn't a story submission. We filter the score just as before. Then we navigate across all the edges we need until we get to the GitHub Actions invoked by that repository's workflows.
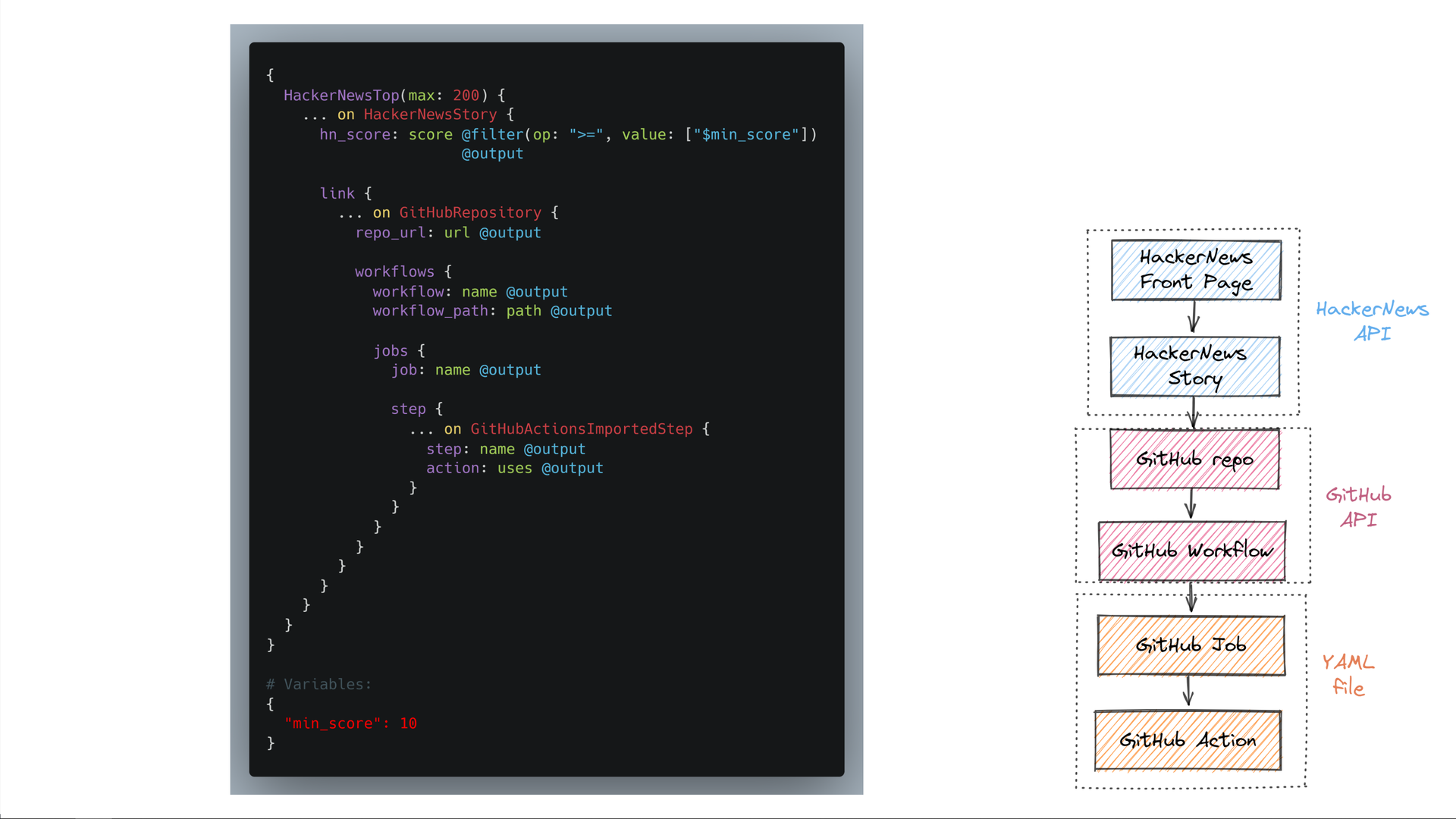
Enough talk — let's see it run! (You can try it yourself by grabbing the code from GitHub!)

Click to replay the animation above
In just a couple of seconds, our query successfully executed dozens of requests against the HackerNews and GitHub APIs on our behalf, and returned all the data we requested. [Sidenote: Our demo was hardcoded to return only 20 results, but Trustfall queries are lazily evaluated so it isn't necessary to specify a particular number of desired results up front. Running a query returns an iterator that lazily yields query results. If the iterator is exhausted, all possible results were retrieved. If a partial result is sufficient, one may stop advancing the iterator at any time.]
Let's take a deeper look at the data we got back.
First, we see that we got data for multiple different GitHub repositories, each of which got a different number of points on HackerNews.
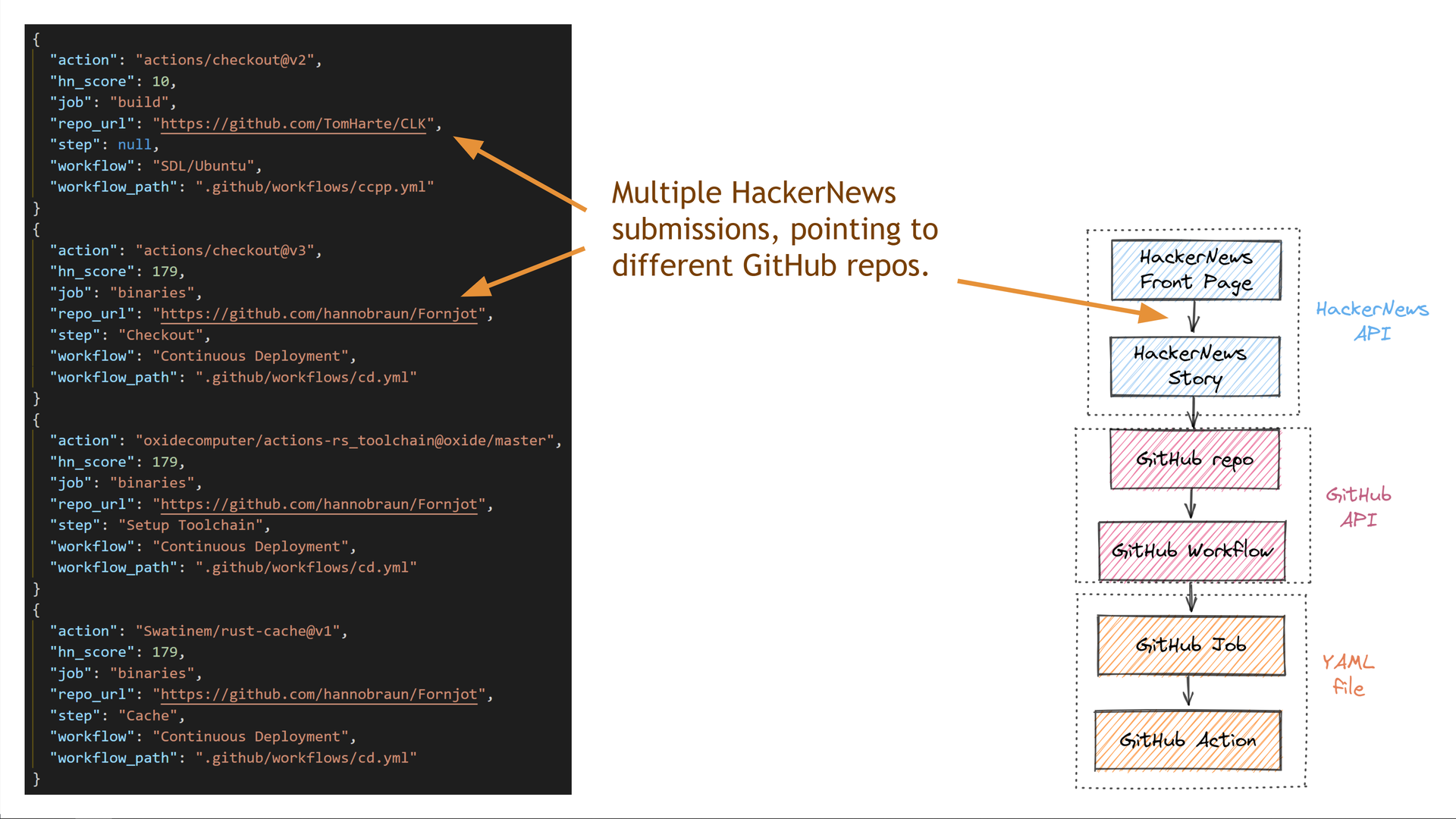
Some of the repositories have multiple jobs within the same GitHub Actions workflow file.

Some repositories also have multiple different workflow files.

The diversity in the returned data shows how our query successfully captured the semantics of the domain we were querying.
How Trustfall executes queries
Jump to this chapter in the video.
The best way to think about Trustfall is that it's like "LLVM for databases." It's structured like a traditional compiler:
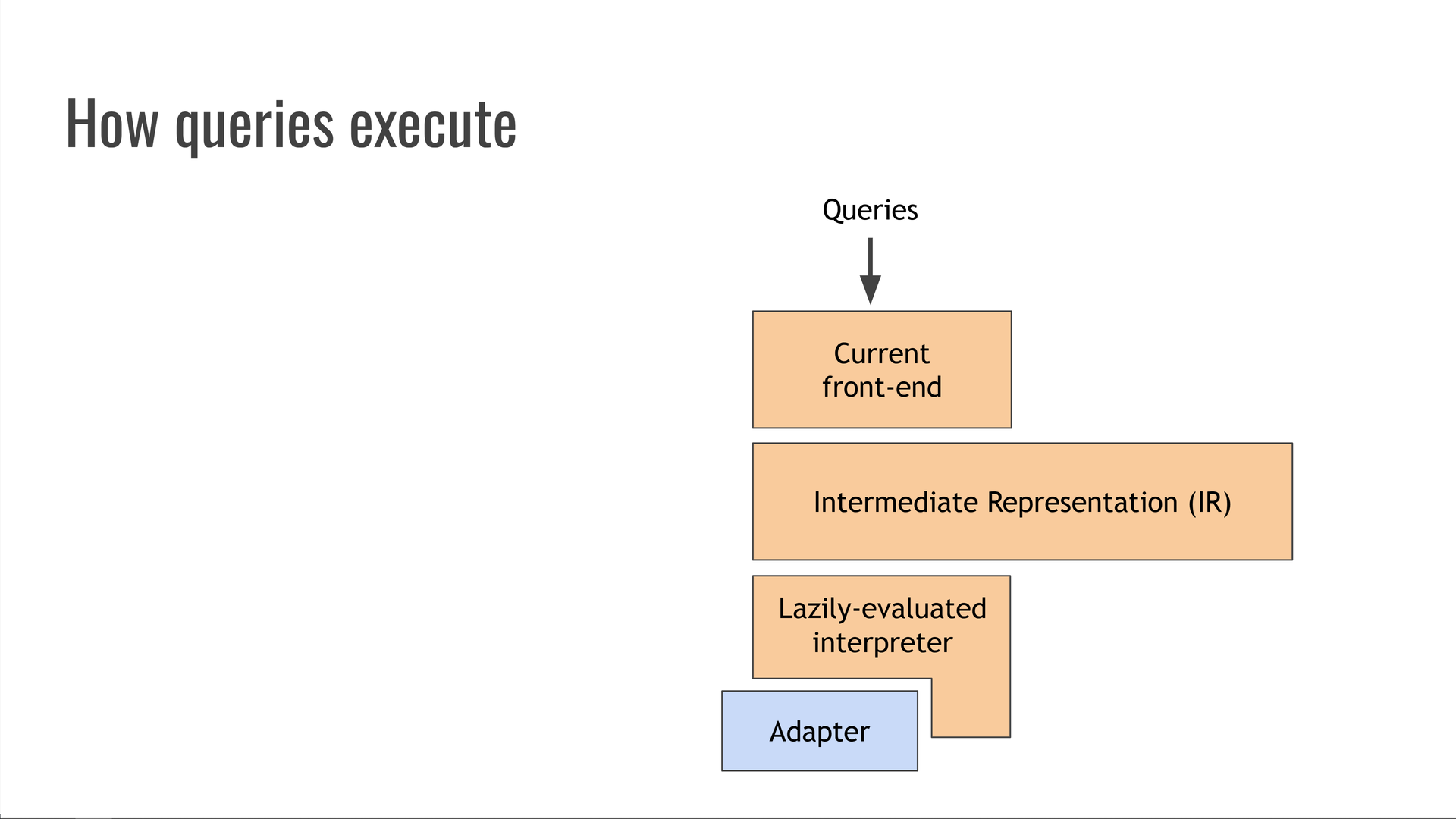
Incoming queries are lexed, parsed, and translated into intermediate representation (IR) in the front end of the compiler.
The IR represents the query without being tied either to the original syntax nor to a specific data source or manner of executing that query.
Currently, the IR is executed by a lazily-evaluated interpreter. Traditionally, this is called a compiler "backend," since it consumes IR and speaks to an underlying system.
Trustfall is a second-generation system and a Rust rewrite of its Python-based predecessor, graphql-compiler, which saw widespread use at Kensho for many years. This post from Kensho's blog shows off some of graphql-compiler's capabilities: it could compile directly to several different database query languages, such as OrientDB MATCH and the SQL dialects for Postgres, Oracle, and Microsoft SQL Server. Its backends also supported estimating query costs, automatic query parallelization and pagination, and many other cool tricks.
Unfortunately, being a fairly old Python project (originally started in Python 2!) meant that the graphql-compiler codebase had accumulated a fair bit of technical debt. Rewriting it in Rust under the name Trustfall offered an opportunity to revisit old design decisions with almost 10 years of hindsight, and substantially improve maintainability and performance in the process.
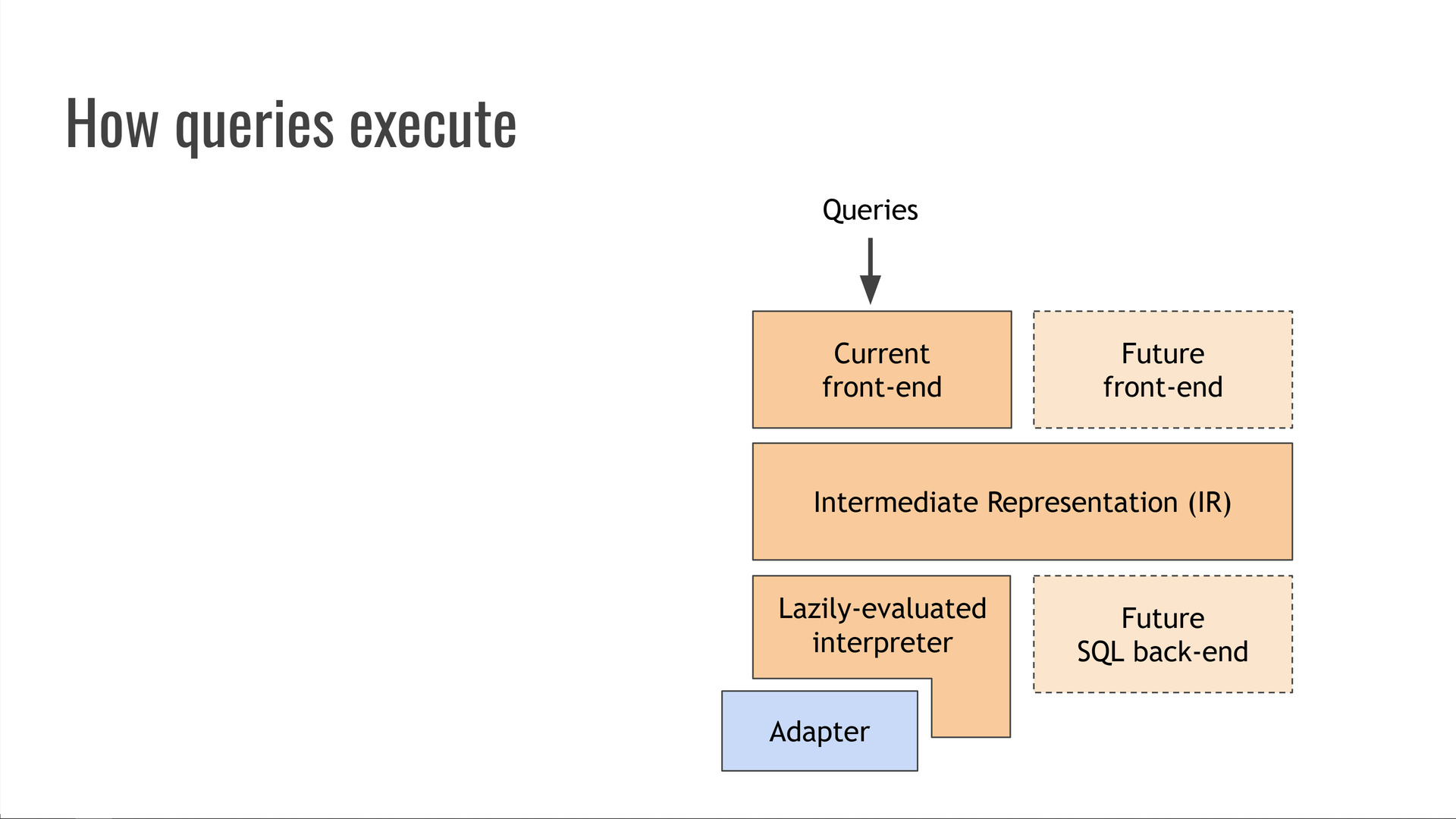
While Trustfall doesn't currently implement all the bells and whistles of graphql-compiler, its design is capable of supporting them in the future. We could add alternative front-ends to accept different query languages, such as GraphQL or SQL. We could also add alternative backends, such as ones that execute queries by compiling them to SQL first.
Hence, like an LLVM for databases.
Why plugging in a new dataset is easy
Jump to this chapter in the video.
All components we've described so far are completely agnostic of the specific data source providing the data for our queries. They are sizable — tens of thousands of lines of code — but they are "write once, use anywhere!"
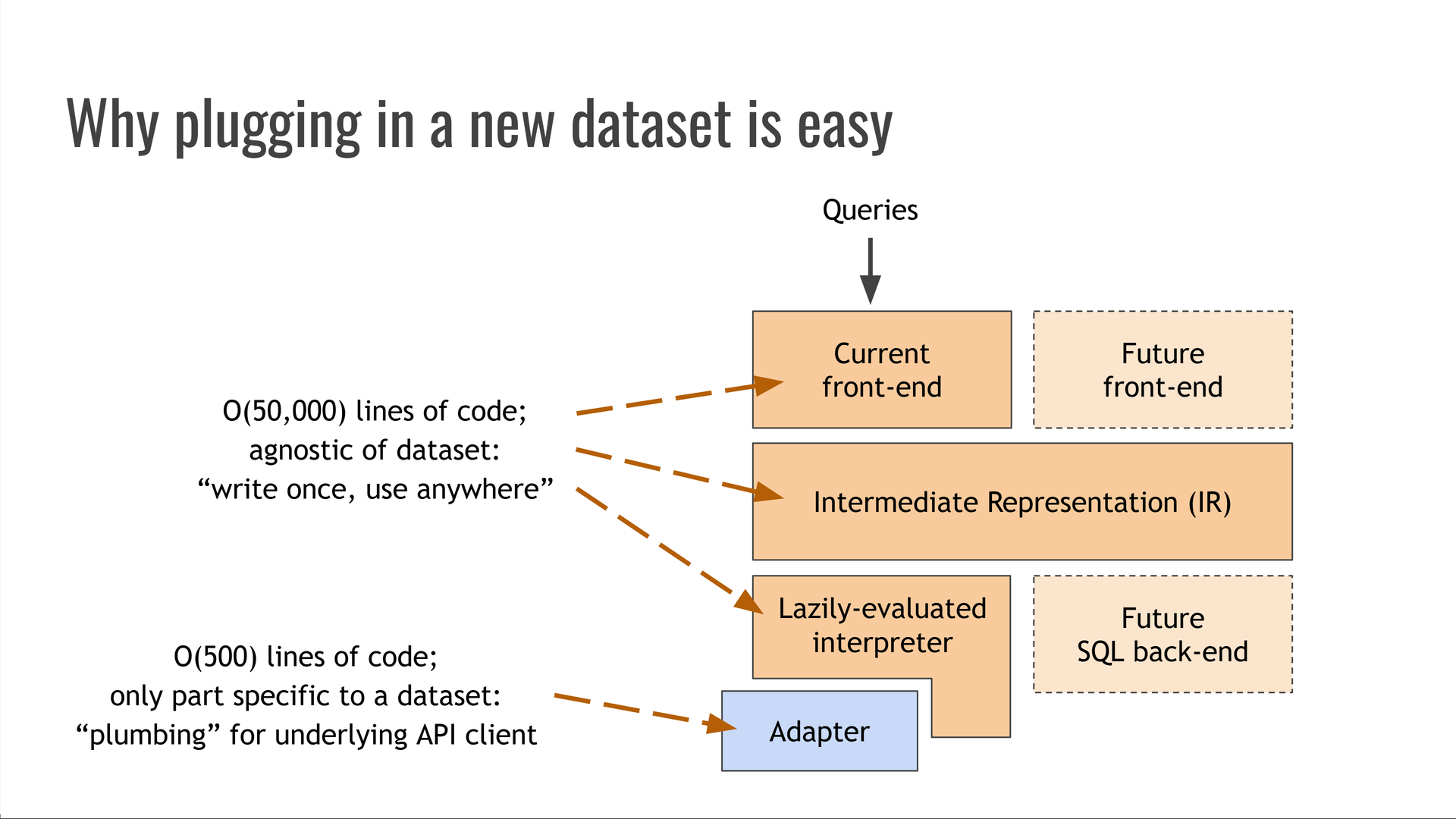
The only component that isn't dataset-agnostic is the adapter module, which acts as plumbing between the interpreter and the underlying API or data file format which contains the data being queried.
The adapter is a massively smaller and simpler piece of code than Trustfall itself — usually, only a few hundred lines of code. It provides a schema — the dataset's vertex types, properties, and edges — which can often be autogenerated e.g. from a database schema or an OpenAPI specification. [Sidenote: For example, the rustdoc JSON adapter that powers cargo-semver-checks can be found in this repository. Its schema is here, and it needs to implement the Trustfall Adapter API defined here. Its Adapter implementation is here. This is one of the more complex adapter implementations, since it needs to precisely model most of the Rust language's semantics for purposes of semver-checking! It was not built monolithically all at once, and instead grew in scope organically over several years.]
Then, the adapter implements four functions that cover operations over that schema:
- Resolve the "entrypoint" of a query, getting an initial set of vertices to work with. For example: fetching the current top-ranked submissions on HackerNews.
- Resolve the value of a specific property on a vertex, like getting a HackerNews submission's score.
- Resolve an edge, starting from a vertex and getting its neighboring vertices along that edge. For example, getting the
Webpagevertex (if any) that a HackerNews story points to. - Resolve a vertex subtyping relationship analogous to Python's
isinstance()operator, such as answering "Is thisWebpagevertex actually aGitHubRepositoryvertex?"

Having written or auto-generated a schema, and having implemented these four functions, we're ready to query any dataset with a fast, modern query language!
We've only scratched the surface!
Jump to this chapter in the video.
Having all our data available in a single query system gives us a tremendous amount of leverage to build interesting tools. In this talk, we've only just scratched the surface of what is possible with this technology. [Sidenote: Today, the cargo-semver-checks linter for semantic versioning in Rust is another example of the possibilities Trustfall unlocks.]
I'll give a couple of brief examples of some of the more unexpected use cases.

One of them is our ability to query schemas, queries, and query plans.
Just like we can query the data behind an API, we can also query the shape of the data itself. We can ask questions like:
- Which of our queries apply filters on property
Xof typeY? - Which types in our schema have string-typed fields with names ending in
date?
The other example is that we can use record-and-replay query tracing to help us understand, audit, and debug our queries.
In fact, this is a big part of how Trustfall's own test suite works! We record traces that capture every operation performed as part of executing all our test queries, then replay the traces against our interpreter as a snapshot test to ensure its behavior hasn't changed. The traces are a linearized, human-readable record that shows which data was produced when, and are perfect for ensuring the correctness of Trustfall and its adapters.
If you'd like to dig deeper, check out:
- Trustfall's GitHub page: https://github.com/obi1kenobi/trustfall
- The demo code for this talk: https://github.com/obi1kenobi/trustfall/tree/main/demo-hytradboi
- Our playgrounds, where you can query HackerNews APIs or the contents of popular Rust packages
cargo-semver-checks, a linter for semantic versioning in Rust written using Trustfall and the subject of other talks I've given
Trustfall gives us an unprecedented amount of leverage, unlike anything open-source tools could call upon before. It's a foundational piece of infrastructure for powerful tools, and so far, we've only just scratched the surface!
If you liked this post, consider subscribing to my blog or following me on Mastodon, Bluesky, or Twitter/X. I'm giving a related talk at the UA Rust Conference 2024, so be sure to check it out!